Es soll eine Liste von Wörtern mit insgesamt ![]() Buchstaben in
Buchstaben in ![]() sortiert werden.
Pro Buchstabe des Alphabets existiert ein Bucket.
sortiert werden.
Pro Buchstabe des Alphabets existiert ein Bucket.
Zunächst wird angenommen, dass
alle Wörter die Länge ![]() haben.
haben.
Es werden sukzessive Listen
![]() gebildet.
gebildet.
![]() enthält die unsortierten Wörter in der gegebenen initialen Reihenfolge.
enthält die unsortierten Wörter in der gegebenen initialen Reihenfolge.
![]() mit
mit
![]() enthält alle Wörter, aufsteigend
sortiert bezüglich der
Positionen
enthält alle Wörter, aufsteigend
sortiert bezüglich der
Positionen
![]() .
.
Das Ergebnis der
Sortiervorgänge ist ![]() .
.
Beispiel:for (j = N; j > 0; j--) {
verteile die Wörter aus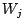
gemäß-tem Buchstaben
auf die Buckets;
sammele Buckets auf nach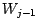
}
Zu sortieren seien die Strings
hefe bach gaga cafe geha
Es entstehen nacheinander folgende Listen (unterstrichen ist jeweils der Buchstabe, der im nächsten Schritt zum Verteilen benutzt wird):
|
|
hefe bach gaga cafe geha |
|
|
gaga geha hefe cafe bach |
|
|
bach hefe cafe gaga geha |
|
|
bach cafe gaga hefe geha |
|
|
bach cafe gaga geha hefe |
Die zugehörigen Buckets lauten:
|
|
|
|
|
|
| a | gaga geha | bach cafe gaga | ||
| b | bach | |||
| c | bach | cafe | ||
| d | ||||
| e | hefe cafe | hefe geha | ||
| f | hefe cafe | |||
| g | gaga | gaga geha | ||
| h | bach | geha | hefe |
Beim Aufsammeln werden die Buckets in alphabetischer Reihenfolge durchlaufen und ihre Inhalte konkateniert.
Um beim Einsammeln der Buckets nur die gefüllten anzufassen, ist es hilfreich, zu Beginn
char[][] nichtleer;
anzulegen.
nichtleer[j]
enthält die Buchstaben,
welche in den zu sortierenden Wörtern an
pos[x]=![]() Buchstabe
Buchstabe ![]() kommt an
kommt an ![]() -ter Position vor }
-ter Position vor }
| x | pos[x] |
| a | 2 2 4 2 4 |
| b | 1 |
| c | 3 1 |
| d | |
| e | 2 4 4 2 |
| f | 3 3 |
| g | 1 3 1 |
| h | 1 4 3 |
Nach dem Einsammeln der Buckets werden die Buchstaben auf Positionen verteilt:
| j | nichtleer[j] |
| 1 | b c g g h |
| 2 | a a a e e |
| 3 | c f f g h |
| 4 | a a e e h |
Bei Vermeidung der Doppelten hat nichtleer[j] folgende Gestalt:
| j | nichtleer[j] |
| 1 | b c g h |
| 2 | a e |
| 3 | c f g h |
| 4 | a e h |
Der Aufwand zur Konstruktion von nichtleer
beträgt ![]() .
Jedes Wort wird bzgl. jedes Buchstabens
einmal verteilt und einmal aufgesammelt,
jeweils in konstanter Zeit.
.
Jedes Wort wird bzgl. jedes Buchstabens
einmal verteilt und einmal aufgesammelt,
jeweils in konstanter Zeit.
Bei Wörtern unterschiedlicher Länge bilde zunächst
laenge[j] =Länge von Wort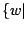
Der Aufwand hierfür beträgt ![]() .
.
Verteile im ![]() -ten Durchlauf zunächst
alle Wörter aus laenge[j];
-ten Durchlauf zunächst
alle Wörter aus laenge[j];
z.B. fad
wird bzgl. des 3. Buchstabens verteilt, bevor ![]() verteilt wird.
verteilt wird.
Der Aufwand zum Verteilen und Aufsammeln der
Listen
![]() beträgt
beträgt ![]() , da jedes
Zeichen einmal zum Verteilen benutzt wird und einmal
beim Aufsammeln unter Vermeidung der nichtleeren Buckets zu einem
Schritt beiträgt.
, da jedes
Zeichen einmal zum Verteilen benutzt wird und einmal
beim Aufsammeln unter Vermeidung der nichtleeren Buckets zu einem
Schritt beiträgt.
Zum Vergleich: Konventionelles Sortieren (z.B. mit Quicksort) einer
Sequenz von mehreren Strings der Gesamtlänge ![]() würde
würde
![]() Aufwand verursachen:
Aufwand verursachen:
Gegeben seien ![]() Strings, jeweils der Länge
Strings, jeweils der Länge ![]() . Es
entstehen
. Es
entstehen
![]() Vergleiche, die allerdings
nicht mehr in konstanter Zeit durchgeführt werden können, sondern
jeweils
Vergleiche, die allerdings
nicht mehr in konstanter Zeit durchgeführt werden können, sondern
jeweils ![]() Schritte benötigen. Also ergibt sich
Schritte benötigen. Also ergibt sich