![]()
![]()
![]()
Betrachten wir das Index-File als Daten-File, so können wir dazu ebenfalls einen weiteren Index konstruieren und für dieses File wiederum einen Index usw. Diese Idee führt zum B*-Baum.
Ein B*-Baum mit Parameter k wird charakterisiert durch folgende Eigenschaften:
Der Baum T befindet sich im Hintergrundspeicher, und zwar
nimmt jeder Knoten einen Block ein. Ein Knoten mit j Nachfolgern
speichert j Paare von Schlüsseln und Adressen
(s1, a1),...,(sj, aj) . Es gilt
s1 ![]() s2
s2 ![]() ..
.. ![]() sj .
Eine Adresse in einem Blattknoten bezeichnet den Datenblock mit
den restlichen Informationen
zum zugehörigen Schlüssel, sonst bezeichnet sie den Block
zu einem Baumknoten: Enthalte der Block für Knoten p die Einträge
(s1,a1),...,(sj,aj) . Dann ist der erste Schlüssel im i-ten
Sohn von p gleich si , alle weiteren Schlüssel
in diesem Sohn (sofern vorhanden) sind größer
als si und kleiner als si + 1 .
sj .
Eine Adresse in einem Blattknoten bezeichnet den Datenblock mit
den restlichen Informationen
zum zugehörigen Schlüssel, sonst bezeichnet sie den Block
zu einem Baumknoten: Enthalte der Block für Knoten p die Einträge
(s1,a1),...,(sj,aj) . Dann ist der erste Schlüssel im i-ten
Sohn von p gleich si , alle weiteren Schlüssel
in diesem Sohn (sofern vorhanden) sind größer
als si und kleiner als si + 1 .
Wir betrachten nur die Operationen auf den Knoten des Baumes und nicht auf den eigentlichen Datenblöcken. Gegeben sei der Schlüssel s .
Abbildung 4.11 zeigt das dynamische Verhalten eines B*-Baums mit dem Parameter k = 2 . Es werden nacheinander die Schlüssel 3, 7, 1, 16, 4, 14, 12, 6, 2, 15, 13, 8, 10, 5, 11, 9 eingefügt und insgesamt 8 Schnappschüsse gezeichnet.
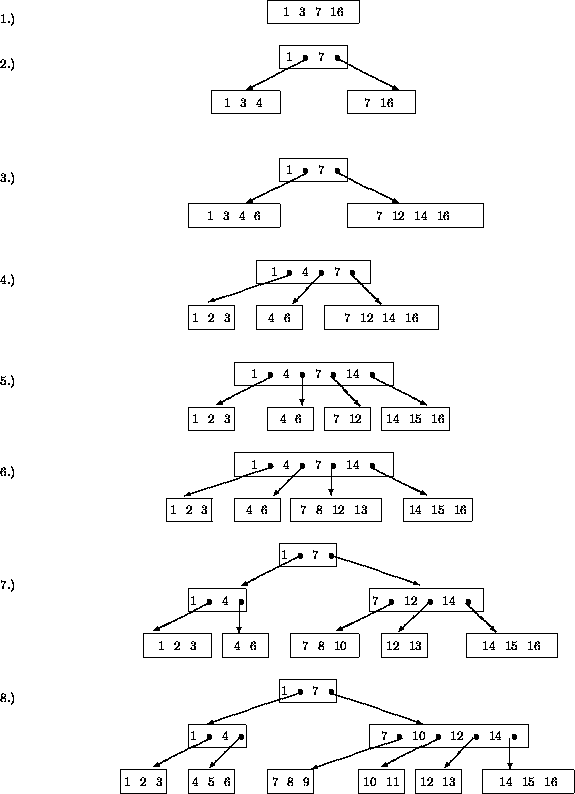
Der Parameter k ergibt sich aus dem Platzbedarf für die Schlüssel/Adreßpaare und der Blockgröße. Die Höhe des Baumes ergibt sich aus der benötigten Anzahl von Verzweigungen, um in den Blättern genügend Zeiger auf die Datenblöcke zu haben.
![]()
![]()
![]() = 53
= 53 ![]() k = 26
k = 26
Die Wurzel sei im Mittel zu 50 % gefüllt (hat also
26 Söhne), ein innerer Knoten sei im Mittel zu
75 % gefüllt (hat also 39 Söhne), ein Datenblock
sei im Mittel zu 75 % gefüllt (enthält also 7
bis 8 Datenrecords).
300.000 Records sind also auf
![]()
![]()
![]() = 40.000
Datenblöcke verteilt.
= 40.000
Datenblöcke verteilt.
Die Zahl der Zeiger entwickelt sich daher auf den oberen Ebenen des Baums wie folgt:
| Höhe | Anzahl Knoten | Anzahl Zeiger | ||
| 0 | 1 | 26 | ||
| 1 | 26 | 26 · 39 | = | 1.014 |
| 2 | 26 · 39 | 26 · 39 · 39 | = | 39.546 |
Damit reicht die Höhe 2 aus, um genügend Zeiger auf die Datenblöcke bereitzustellen. Der Platzbedarf beträgt daher
1 + 26 + 26 · 39 + 39546 ![]() 40.000Blöcke.
40.000Blöcke.
Das LOOKUP auf ein Datenrecord verursacht also vier Blockzugriffe: es werden drei Indexblöcke auf Ebene 0, 1 und 2 sowie ein Datenblock referiert. Zum Vergleich: Das Heapfile benötigt 30.000 Blöcke.
Soll für offenes Hashing eine mittlere
Zugriffszeit von 4 Blockzugriffen gelten,
so müssen in jedem Bucket etwa 5
Blöcke sein (1 Zugriff für Hash-Directory,
3 Zugriffe im Mittel für eine Liste von 5 Blöcken).
Von diesen 5 Blöcken sind 4 voll, der
letzte halbvoll. Da 10 Records in einen Datenblock passen,
befinden sich in einem Bucket etwa
4,5 · 10 = 45 Records.
Also sind
![]() = 6.666 Buckets erforderlich.
Da 256 Adressen in einen Block passen, werden
= 6.666 Buckets erforderlich.
Da 256 Adressen in einen Block passen, werden
![]()
![]()
![]() = 26 Directory-Blöcke benötigt.
Der Platzbedarf beträgt daher
26 + 5 · 6666 = 33356 .
= 26 Directory-Blöcke benötigt.
Der Platzbedarf beträgt daher
26 + 5 · 6666 = 33356 .
Zur Bewertung von B*-Bäumen läßt sich sagen: