Die grundsätzliche Aufgabe bei der Realisierung eines internen Modells besteht aus dem Abspeichern von Datentupeln, genannt Records, in einem File. Jedes Record hat ein festes Record-Format und besteht aus mehreren Feldern meistens fester, manchmal auch variabler Länge mit zugeordnetem Datentyp. Folgende Operationen sind erforderlich:
Files werden abgelegt im Hintergrundspeicher (Magnetplatte), der aus Blöcken fester Größe (etwa 29 - 212 Bytes) besteht, die direkt adressierbar sind. Ein File ist verteilt über mehrere Blöcke, ein Block enthält mehrere Records. Records werden nicht über Blockgrenzen verteilt. Einige Bytes des Blockes sind unbenutzt, einige werden für den header gebraucht, der Blockinformationen (Verzeigerung, Record-Interpretation) enthält.
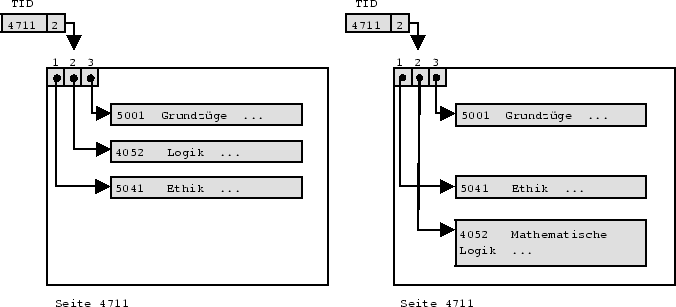
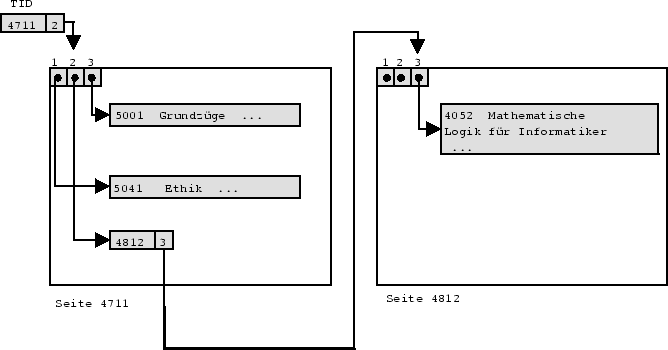
Die Adresse eines Records besteht entweder aus der Blockadresse und einem Offset (Anzahl der Bytes vom Blockanfang bis zum Record) oder wird durch den sogenannten Tupel-Identifikator (TID) gegeben. Der Tupel-Identifikator besteht aus der Blockadresse und einer Nummer eines Eintrags in der internen Datensatztabelle, der auf das entsprechende Record verweist. Sofern genug Information bekannt ist, um ein Record im Block zu identifizieren, reicht auch die Blockadresse. Blockzeiger und Tupel-Identifikatoren erlauben das Verschieben der Records im Block ( unpinned records), Record-Zeiger setzen fixierte Records voraus ( pinned records), da durch Verschieben eines Records Verweise von außerhalb mißinterpretiert würden ( dangling pointers).
Abbildung 4.1 zeigt das Verschieben eines Datentupels innerhalb seiner ursprünglichen Seite; in Abbildung 4.2 wird das Record schließlich auf eine weitere Seite verdrängt.
Das Lesen und Schreiben von Records kann nur im Hauptspeicher geschehen. Die Blockladezeit ist deutlich größer als die Zeit, die zum Durchsuchen des Blockes nach bestimmten Records gebraucht wird. Daher ist für Komplexitätsabschätzungen nur die Anzahl der Blockzugriffe relevant.
Zur Umsetzung des Entity-Relationship-Modells verwenden wir