Offenes und auch erweiterbares Hashing sind nicht in der Lage, Datensätze in sortierter Reihenfolge auszugeben oder Bereichsabfragen zu bearbeiten. Für Anwendungen, bei denen dies erforderlich ist, kommen Index-Strukturen zum Einsatz (englisch: index sequential access method = ISAM) Wir setzen daher voraus, daß sich die Schlüssel der zu verwaltenden Records als Zeichenketten interpretieren lassen und damit eine lexikographische Ordnung auf der Menge der Schlüssel impliziert wird. Sind mehrere Felder am Schlüssel beteiligt, so wird zum Vergleich deren Konkatenation herangezogen.
Neben der Haupt-Datei (englisch: main file), die alle Datensätze in
lexikographischer Reihenfolge enthält, gibt es nun
eine Index-Datei (english: index file) mit Verweisen in die Hauptdatei.
Die Einträge der Index-Datei sind Tupel, bestehend aus Schlüsseln und
Blockadressen, sortiert nach Schlüsseln. Liegt ![]() in der
Index-Datei, so sind alle Record-Schlüssel im Block, auf den
in der
Index-Datei, so sind alle Record-Schlüssel im Block, auf den ![]() zeigt,
größer oder gleich
zeigt,
größer oder gleich ![]() . Zur Anschauung: Fassen wir ein
Telefonbuch als Hauptdatei auf (eine Seite
. Zur Anschauung: Fassen wir ein
Telefonbuch als Hauptdatei auf (eine Seite ![]() ein Block), so
bilden alle die Namen, die jeweils links oben auf den Seiten vermerkt sind,
einen Index.
Da im Index nur ein Teil der Schlüssel aus der Hauptdatei zu finden sind,
spricht man von einer dünn besetzten Index-Datei
(englisch: sparse index).
ein Block), so
bilden alle die Namen, die jeweils links oben auf den Seiten vermerkt sind,
einen Index.
Da im Index nur ein Teil der Schlüssel aus der Hauptdatei zu finden sind,
spricht man von einer dünn besetzten Index-Datei
(englisch: sparse index).
Wir nehmen an, die Records seien verschiebbar und pro Block sei im Header vermerkt, welche Subblocks belegt sind. Dann ergeben sich die folgenden Operationen:
Bemerkung: Ist die Verteilung der Schlüssel bekannt,
so sinkt für ![]() Index-Blöcke
die Suchzeit durch Interpolation Search
auf
Index-Blöcke
die Suchzeit durch Interpolation Search
auf ![]() Schritte!
Schritte!
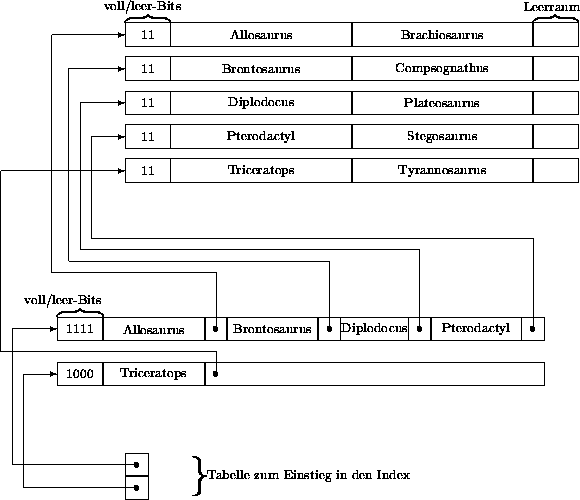
Abbildung 4.6 zeigt die Ausgangslage für eine Hauptdatei mit Blöcken, die jeweils 2 Records speichern können. Die Blöcke der Index-Datei enthalten jeweils vier Schlüssel/Adreß-Paare. Weiterhin gibt es im Hauptspeicher eine Tabelle mit Verweisen zu den Index-Datei-Blöcken.
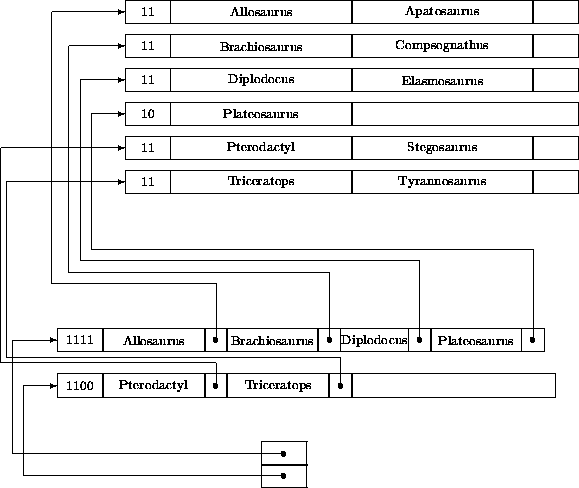
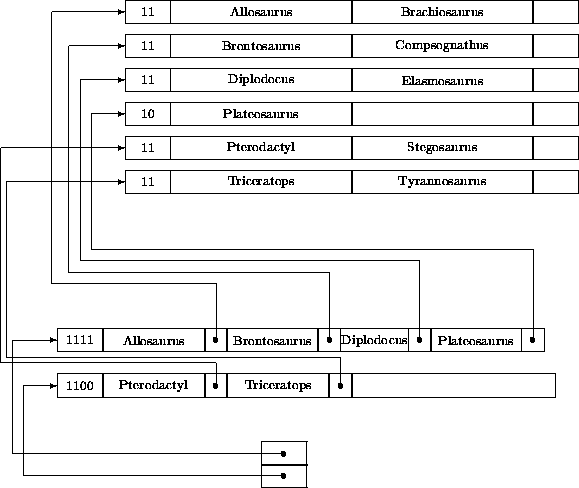
Abbildung 4.7 zeigt die Situation nach dem Einfügen von Elasmosaurus. Hierzu findet man zunächst als Einstieg Diplodocus. Der zugehörige Dateiblock ist voll, so daß nach Einfügen von Elasmosaurus für das überschüssige Record Plateosaurus ein neuer Block angelegt und sein erster Schlüssel in die Index-Datei eingetragen wird.
Nun wird Brontosaurus umbenannt in Apatosaurus. Hierzu wird zunächst Brontosaurus gelöscht, sein Dateinachfolger Compsognathus um einen Platz vorgezogen und der Schlüssel in der Index-Datei, der zu diesem Blockzeiger gehört, modifiziert. Das Einfügen von Apatosaurus bewirkt einen Überlauf von Brachiosaurus in den Nachfolgeblock, in dem Compsognathus nun wieder an seinen alten Platz rutscht. Im zugehörigen Index-Block verschwindet daher sein Schlüssel wieder und wird überschrieben mit Brachiosaurus (Abbildung 4.8).