Als Beispiel für einen heftig genutzten Index soll die grundsätzliche Vorgehensweise bei der Firma Google besprochen werden.
Google wurde 1998 von Sergey Brin und Larry Page gegründet und ist inzwischen auf 2500 Mitarbeiter angewachsen. Die Oberfläche der Suchmaschine wird in mehr als 100 Sprachen angeboten. Etwa 8 Milliarden Webseiten liegen im Cache, der mehr als 40 TeraByte an Plattenplatz belegt. Im Lexikon befinden sich etwa 14 Millionen Schlüsselwörter, nach denen täglich mit mehr als 100 Millionen Queries gefragt wird.
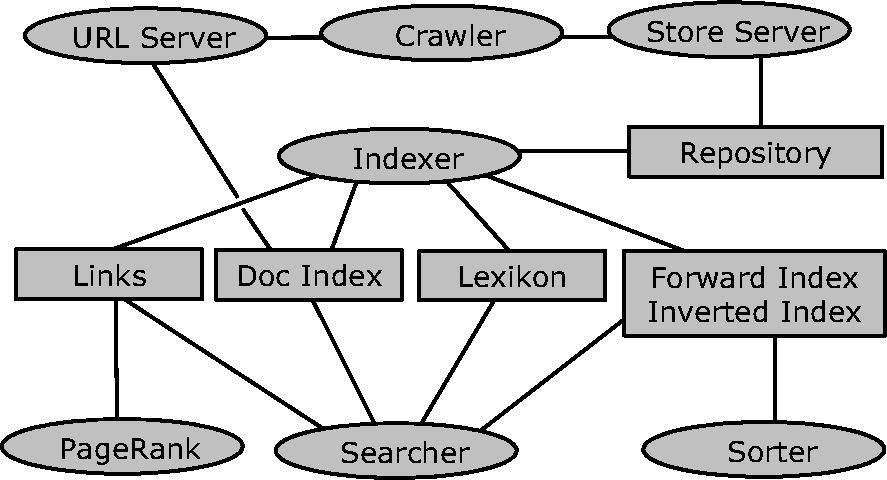
Abbildung 4.13 zeigt die prinzipielle Systemarchitektur: Der URL-Server generiert eine Liste von URLs, welche vom Crawler systematisch besucht werden. Dabei werden neu entdeckte URLs im DocIndex abgelegt. Der Store Server legt den kompletten, abgerufenen HTML-Text eines besuchten Dokuments in komprimierter Form im Repository ab. Der Indexer verarbeitet den Repository-Inhalt: Jedem Dokument wird eine eindeutige docID zugeteilt. Aus jedem HREF-Konstrukt, welches von Seite A zur Seite B zeigt, wird ein Paar (docID(A), docID(B)) erzeugt und in der Liste aller Verweis-Paare eingefügt (Links). Jedes beobachtete Schlüsselwort wird ins Lexikon eingetragen zusammen mit einer eindeutigen wordID, der Zahl der relevanten Dokumente und einem Verweis auf die erste Seite des Inverted Index, auf der solche docIDs liegen, in dessen Dokumenten dieses Wort beobachtet wurde oder auf die es innerhalb eines Anchor-Textes verweist.
Die Zeilen im Lexikon haben daher die Struktur
wordID #docs pointer wordID #docs pointer wordID #docs pointer wordID #docs pointer
Durch Inspektion der Webseiten im Repository erstellt der Indexer zunächst den Forward Index, welcher zu jedem Dokument und jedem Wort die Zahl der Hits und ihre Positionen notiert.
Die Struktur im Forward Index lautet
docID wordID #hits hit hit hit hit hit hit
wordID #hits hit hit hit
docID wordID #hits hit hit hit hit
wordID #hits hit hit hit hit hit
wordID #hits hit hit hit hit
Daraus erzeugt der Sorter den Inverted Index, welcher folgende Struktur aufweist:
wordID docID #hits hit hit hit hit hit hit
docID #hits hit hit hit
docID #hits hit hit hit hit hit
wordID docID #hits hit hit hit hit
docID #hits hit hit hit hit hit
Aus technischen Gründen ist der Forward Index bereits auf 64 Barrels verteilt, die jeweils für einen bestimmten WordID-Bereich zuständig sind. Hierdurch entsteht beim Einsortieren zwar ein Speicheroverhead, da die Treffer zu einer docID sich über mehrere Barrels verteilen, aber die anschließende Sortierphase bezieht sich jeweils auf ein Barrel und kann daher parallelisiert werden.
Jeder hit umfasst zwei Bytes: 1 Capitalization Bit, 3 Bits für die Größe des verwendeten Fonts und 12 Bit für die Adresse im Dokument. Dabei werden alle Positionen größer als 4095 auf diesen Maximalwert gesetzt. Es wird unterschieden zwischen plain hits, welche innerhalb von normalem HTML auftauchen, und fancy hits, welche innerhalb einer URL, eines HTML-Title, im Anchor-Text oder in einem Meta-Tag auftauchen.
Der PageRank-Algorithmus berechnet auf Grundlage der Seitenpaare in der Datei Links die sogenannte Link Popularität, welche ein Maß für die Wichtigkeit einer Seite darstellt: Eine Seite ist wichtig, wenn andere wichtige Seiten auf sie verweisen.
Zur formalen Berechnung machen wir folgende Annahmen:
Seite ![]() habe
habe ![]() ausgehende Links. Auf Seite
ausgehende Links. Auf Seite ![]() mögen
die Seiten
mögen
die Seiten
![]() verweisen. Gegeben sei ein
Dämpfungsfaktor
verweisen. Gegeben sei ein
Dämpfungsfaktor
![]() . (1-d) modelliert die
Wahrscheinlichkeit, dass ein Surfer im Web eine Seite
nicht über einen Link findet, sondern eine Verweiskette
schließlich abbricht und die Seite
spontan anwählt.
. (1-d) modelliert die
Wahrscheinlichkeit, dass ein Surfer im Web eine Seite
nicht über einen Link findet, sondern eine Verweiskette
schließlich abbricht und die Seite
spontan anwählt.
Dann ergibt sich der PageRank
von Seite ![]() wie folgt:
wie folgt:
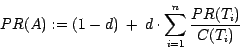
Je wichtiger Seite ![]() ist (großes
ist (großes ![]() )
und je weniger ausgehende Links sie hat (kleines
)
und je weniger ausgehende Links sie hat (kleines ![]() ), desto
mehr strahlt von ihrem Glanz etwas auf Seite
), desto
mehr strahlt von ihrem Glanz etwas auf Seite ![]() .
.
Hierdurch entsteht ein Gleichungssystem, welches sich durch ein Iterationsverfahren lösen lässt; Google braucht dafür ein paar Stunden.
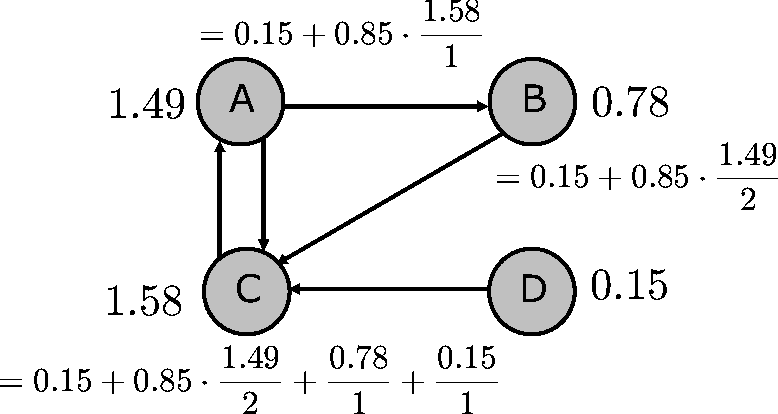
Abbildung 4.14 zeigt ein Mini-Web mit vier
untereinander verzeigerten Seiten ![]() zusammen mit den ermittelten
PageRanks, basierend auf einem Dämpfungsfaktor von
zusammen mit den ermittelten
PageRanks, basierend auf einem Dämpfungsfaktor von ![]() .
.
Der vorberechnete PageRank und der vorberechnete Inverted Index erlauben nun eine effiziente Suche nach einem oder mehreren Schlüsselwörtern.
Bei einer Single-Word-Query ![]() werden zunächst mit Hilfe des
Inverted Index alle Seiten ermittelt,
in denen
werden zunächst mit Hilfe des
Inverted Index alle Seiten ermittelt,
in denen ![]() vorkommt. Für jede ermittelte Seite
vorkommt. Für jede ermittelte Seite ![]() werden die Hit-Listen ausgewertet bzgl. des
Treffer-Typs (abnehmende Wichtigkeit für Treffer in
title, anchor, URL, plain text large font, plain text small font,
...). Der gewichtete Treffervektor wird skalar multipliziert mit
dem Trefferhäufigkeitsvektor und ergibt den Weight-Score(d,w).
Dieser wird nach einem geheimen Google-Rezept
mit dem PageRank(d) kombiniert und es entsteht der
Final-Score(d,w),
welcher durch Sortieren die Trefferliste bestimmt.
werden die Hit-Listen ausgewertet bzgl. des
Treffer-Typs (abnehmende Wichtigkeit für Treffer in
title, anchor, URL, plain text large font, plain text small font,
...). Der gewichtete Treffervektor wird skalar multipliziert mit
dem Trefferhäufigkeitsvektor und ergibt den Weight-Score(d,w).
Dieser wird nach einem geheimen Google-Rezept
mit dem PageRank(d) kombiniert und es entsteht der
Final-Score(d,w),
welcher durch Sortieren die Trefferliste bestimmt.
Bei einer Multi-Word-Query
![]() werden
zunächst 10 Entfernungsklassen gebildet (von 'unmittelbar benachbart'
bis 'sehr weit entfernt') und als Grundlage für einen
sogenannten Proximity-Score
werden
zunächst 10 Entfernungsklassen gebildet (von 'unmittelbar benachbart'
bis 'sehr weit entfernt') und als Grundlage für einen
sogenannten Proximity-Score
![]() ausgewertet: nah
in einem Dokument beeinanderliegende
Suchwörter werden belohnt.
Dann wird für jede gemeinsame Trefferseite
ausgewertet: nah
in einem Dokument beeinanderliegende
Suchwörter werden belohnt.
Dann wird für jede gemeinsame Trefferseite ![]() und jedes Suchwort
und jedes Suchwort ![]() der konventionelle
Weight-Score
der konventionelle
Weight-Score![]() kombiniert mit dem
Proximity-Rank
kombiniert mit dem
Proximity-Rank
![]() und dem PageRank(d).
Der dadurch errechnete
Final-Score
und dem PageRank(d).
Der dadurch errechnete
Final-Score
![]() bestimmt nach dem Sortieren
die Trefferliste.
bestimmt nach dem Sortieren
die Trefferliste.