


Als Alternative zu den Verfahren
mit fester Gittergröße
stellten Hinrichs und Nievergelt im Jahre 1981 das
Grid File vor, welches auch bei dynamisch sich änderndem
Datenbestand eine 2-Platten-Zugriffsgarantie gibt.
Erreicht wird dies (bei 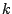 -dimensionalen Tupeln) durch
-dimensionalen Tupeln) durch
- Skalen zum Einstieg ins Grid-Directory (im Hauptspeicher)
- Grid-Directory zum Finden der Bucket-Nr. (im Hintergrundspeicher)
- Buckets für Datensätze (im Hintergrundspeicher)
Zur einfacheren Veranschaulichung beschreiben wir
die Technik für Dimension 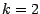 . Verwendet werden dabei
. Verwendet werden dabei
- zwei eindimensionale Skalen,
welche die
momentane Unterteilung der X- bzw. Y-Achse enthalten:
var X: array [0..max_x] of attribut_wert_x;
var Y: array [0..max_y] of attribut_wert_y;
- ein 2-dimensionales Grid-Directory,
welches Verweise auf die Datenblöcke enthält:
var G: array [0..max_x - 1, 0..max_y - 1] of pointer;
D.h. G[i, j] enthält eine Bucketadresse, in
der ein rechteckiger Teilbereich der Datenpunkte
abgespeichert ist. Zum Beispiel sind alle Punkte mit
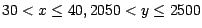 im Bucket mit Adresse G[1,2] zu finden
(in Abbildung 5.8 gestrichelt umrandet).
Achtung: mehrere Gitterzellen können im selben Bucket liegen.
im Bucket mit Adresse G[1,2] zu finden
(in Abbildung 5.8 gestrichelt umrandet).
Achtung: mehrere Gitterzellen können im selben Bucket liegen.
- mehrere Buckets,
welche jeweils
eine maximale Zahl von Datenrecords aufnehmen können.
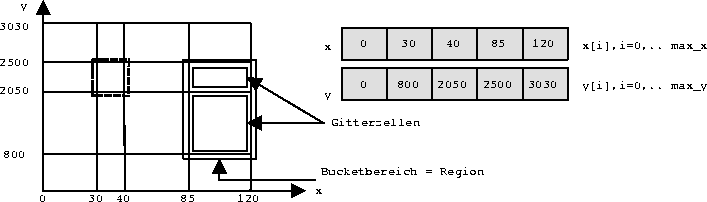
Abbildung
5.8: Skalen und resultierende Gitterzellen
- Beispiel
- für ein Lookup mit
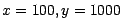 :
:
Suche in Skala 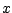 den letzten Eintrag
den letzten Eintrag 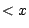 . Er habe den Index
. Er habe den Index 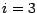 .
.
Suche in Skala 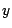 den letzten Eintrag
den letzten Eintrag 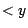 . Er habe den Index
. Er habe den Index 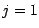 .
.
Lade den Teil des Grid-Directory in den Hauptspeicher, der ![$G[3,1]$](img117.gif) enthält.
enthält.
Lade Bucket mit Adresse .
- Beispiel
- für den Zugriff auf das Bucket-Directory (statisch,
maximale Platznutzung):
Vorhanden seien 32.000 Datentupel, jeweils 5 passen in einen Block.
Die 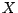 - und die
- und die 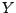 -Achse habe jeweils 80 Unterteilungen.
Daraus ergeben sich 6.400 Einträge für das Bucket-Directory
-Achse habe jeweils 80 Unterteilungen.
Daraus ergeben sich 6.400 Einträge für das Bucket-Directory 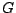 .
Bei 4 Bytes pro Zeiger und 1024 Bytes pro Block passen 256 Zeiger
auf einen Directory-Block. Also gibt es 25 Directory-Blöcke.
D.h.
.
Bei 4 Bytes pro Zeiger und 1024 Bytes pro Block passen 256 Zeiger
auf einen Directory-Block. Also gibt es 25 Directory-Blöcke.
D.h. ![$G[i,j]$](img121.gif) befindet sich auf Block
befindet sich auf Block
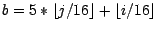 an der
Adresse
an der
Adresse
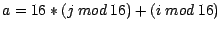 .
.
Bei einer range query, gegeben durch
ein Suchrechteck, werden zunächst alle Gitterzellen bestimmt,
die in Frage kommen, und dann die zugehörenden Buckets eingelesen.