
Die grundlegende Idee beim offenen Hashing ist es, die Records des Files
auf mehrere Behälter (englisch: Bucket) aufzuteilen,
die jeweils aus einer Folge von verzeigerten Blöcken bestehen. Es gibt eine Hash-Funktion ![]() , die
einen Schlüssel als Argument erhält und ihn auf die Bucket-Nummer
abbildet, unter der der Block gespeichert ist, welcher das Record mit diesem
Schlüssel enthält. Sei
, die
einen Schlüssel als Argument erhält und ihn auf die Bucket-Nummer
abbildet, unter der der Block gespeichert ist, welcher das Record mit diesem
Schlüssel enthält. Sei ![]() die Menge der Buckets, sei
die Menge der Buckets, sei ![]() die
Menge der möglichen Record-Schlüssel, dann gilt gewöhnlich
die
Menge der möglichen Record-Schlüssel, dann gilt gewöhnlich
![]() .
.
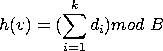

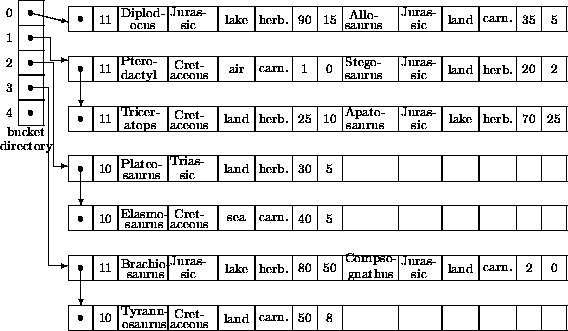
Im Bucket-Directory findet sich als ![]() -ter Eintrag der Verweis auf den
Anfang einer Liste von Blöcken, unter denen das Record mit Schlüssel
-ter Eintrag der Verweis auf den
Anfang einer Liste von Blöcken, unter denen das Record mit Schlüssel ![]() zu finden ist. Abbildung 4.5
zeigt eine Hash-Tabelle, deren Hash-Funktion
zu finden ist. Abbildung 4.5
zeigt eine Hash-Tabelle, deren Hash-Funktion
![]() die Personalnummer
die Personalnummer ![]() durch
durch ![]() mod
mod ![]() auf das Intervall [0..2]
abbildet.
auf das Intervall [0..2]
abbildet.
Falls ![]() klein ist, kann sich das Bucket-Directory im Hauptspeicher
befinden; andernfalls ist es über mehrere Blöcke im
Hintergrundspeicher verteilt,
von denen zunächst der zuständige Block geladen werden muß.
klein ist, kann sich das Bucket-Directory im Hauptspeicher
befinden; andernfalls ist es über mehrere Blöcke im
Hintergrundspeicher verteilt,
von denen zunächst der zuständige Block geladen werden muß.
Jeder Block enthält neben dem Zeiger auf den Folgeblock noch jeweils 1 Bit pro Subblock (Platz für ein Record), welches angibt, ob dieser Subblock leer (also beschreibbar) oder gefüllt (also lesbar) ist. Soll die Möglichkeit von dangling pointers grundsätzlich ausgeschlossen werden, müßten gelöschte Records mit einem weiteren, dritten Zustand versehen werden, der dafür sorgt, daß dieser Speicherplatz bis zum generellen Aufräumen nicht wieder verwendet wird.
Zu einem Record mit Schlüssel ![]() laufen die Operationen wie folgt ab:
laufen die Operationen wie folgt ab:
Der Aufwand aller Operationen hängt davon ab, wie gleichmäßig die Hash-Funktion ihre Funktionswerte auf die Buckets verteilt und wie viele Blöcke im Mittel ein Bucket enthält. Im günstigsten Fall ist nur ein Directory-Zugriff und ein Datenblock-Zugriff erforderlich und ggf. ein Blockzugriff beim Zurückschreiben. Im ungünstigsten Fall sind alle Records in dasselbe Bucket gehasht worden und daher müssen ggf. alle Blöcke durchlaufen werden.
Abbildung 4.6
zeigt die Ausgangssituation. Nun werde
Elasmosaurus (Hashwert = ![]() ) eingefügt. Hierzu muß ein
neuer Block für Bucket
) eingefügt. Hierzu muß ein
neuer Block für Bucket ![]() angehängt werden.
Dann werde Brontosaurus umgetauft in Apatosaurus.
Da diese Änderung den Schlüssel berührt, muß das Record gelöscht
und modifiziert neu eingetragen werden. Abbildung
4.7
zeigt das Ergebnis.
angehängt werden.
Dann werde Brontosaurus umgetauft in Apatosaurus.
Da diese Änderung den Schlüssel berührt, muß das Record gelöscht
und modifiziert neu eingetragen werden. Abbildung
4.7
zeigt das Ergebnis.
Bei geschickt gewählter Hash-Funktion werden sehr kurze Zugriffszeiten erreicht, sofern das Bucket-Directory der Zahl der benötigten Blöcke angepaßt ist. Bei statischem Datenbestand läßt sich dies leicht erreichen. Problematisch wird es bei dynamisch wachsendem Datenbestand. Um immer größer werdende Buckets zu vermeiden, muß von Zeit zu Zeit eine völlige Neuorganisation der Hash-Tabelle durchgeführt werden.