


|
|
|
Hans-Peter Bischof
Fachbereich Mathematik-Informatik
Universität Osnabrück.
Diese Vorlesung ist eine Einführung in die Benutzung von UNIX (Terminal, tty, Dateien und Prozesse) auf der Ebene von Kommandosprachen wie der Bourne-Shell, unter Berücksichtigung der wichtigsten Dienstprogramme.
Dieser Band enthält Kopien der OH-Folien, die in der Vorlesung verwendet wurden. Diese Information steht außerdem im Web (http://zeus/~sp) online zur Verfügung; sie ist in sich und mit der Systemdokumentation über das WWW verbunden.
Die Beispielprogramme werden maschinell aus diesem Text extrahiert. Der Band stellt kein komplettes Manuskript der Vorlesung dar. Zum Selbststudium müßten zusätzlich Bücher über das UNIX-System und speziell über Shell-Programmierung konsultiert werden.
Das Skript hält sich an das Skript von Prof. Axel T. Schreiner aus dem Jahre 1994, größere Passagen wurden daraus entnommen.
Enthaltene Fehler sind ausschließlich mir anzulasten. Es wäre schön, wenn diese an mich berichtet werden würden.
Vorlesung: Dienstag 10:15 - 12.00 31/449a Hans-Peter Bischof
Donnerstag 10.15 - 12.00 31/449a
Sprechstunde Dienstag 8.30 - 10.00 31/318b
Übungen Montag 10:15 - 12.00 31/449a Bernd Kühl
Hans-Peter Bischof Büro: 31/318b email: bischof@informatik.uni-osnabrueck.de Telefon: 0541 / 969 2534 Web: http://thor.informatik.uni-osnabrueck.de/bischof/hp.d.html
Übung:
Bernd Kühl Büro: 31/317 email: bernd@informatik.uni-osnabrueck.de Telefon: 0541 / 969 2487 Web: http://thor.informatik.uni-osnabrueck.de/bischof/bernd.d.html
Diese Folien befinden sich
in PostSkript in: /home/sp/PS/c.[01][0-9]ps in HTML in: /home/sp/public_html/* gedruckt im: Semesterapparat.
Die Programme finden sich unter /home/sp/Skript/Src
Es gibt heute sehr viele Bücher über UNIX und Shell-Programmierung. Entscheidend ist dabei weniger, daß ein Buch möglichst viele Kommandos erklärt, sondern, daß die Möglichkeiten der Zusammenarbeit erläutert werden. Die folgenden Bücher sind nützlich. Soweit vorhanden, befinden sie sich in der Lehrsammlung.
Bourne The UNIX System (viele Auflagen) Gulbins 3-540-13242-2 Unix Kerninghan/Ritchie 3-446-15497-3 Programmieren in C Kernighan/Pike 3-446-14273-8 Der UNIX-WerkzeugkastenZu einzelnen Themen:
Aho/Kernighan/Weinberger 0-201-07981-X The AWK Programming Language Schreiner 3-446-14894-9 UNIX Sprechstunde Wall/Schwartz 0-937175-64-1 Programming perl
Modernere Aspekte der Bourne-Shell wurden in Artikeln in der unix/mail behandelt.
Die Manual-Seiten befinden sich online und können mit dem Kommando man(1) oder auf einer NeXT mit dem Librarian betrachtet werden.
``Das Schöne an UNIX-Standards ist, daß es so viele gibt, daß man sich seinen eigenen aussuchen kann.''
Die drei letzteren sind sich bei naiverer Benutzung ziemlich ähnlich.
Früher wurde ein Rechner von einem separaten Terminal aus benutzt, das über eine serielle Schnittstelle (wenigstens 3 Drähte für full-duplex Betrieb) angeschlossen war. Heute ist am PC oder an der Workstation der Bildschirminhalt meistens direkt im Hauptspeicher und wir verwenden ein Programm zur Terminal-Emulation, aber es gibt nach wie vor serielle Anschlüsse für Modems oder an Terminal-Servern:
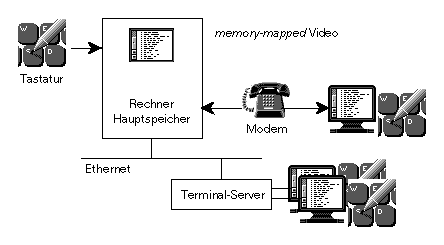
Kommandos ruft man zunächst im Dialog auf. Dazu hat man entweder ein Terminal oder ein Fenster mit einer Terminal-Emulation. Letztlich holt das Betriebssystem Zeichen von der Tastatur ab und schreibt Zeichen auf den Bildschirm. Eine Shell, das heißt, ein Kommando-Interpreter, -- z.B. ksh(1), bash(1), sh(1), csh(1) oder ... -- liest Zeilen und führt die darin beschriebenen Kommandos meistens als eigene Prozesse aus. Siehe auch tty(4).
Eine primitive Shell könnte wie folgt aussehen:
1 #include <stdio.h>
2
3 int read_line(char * buf)
4 { char * help = buf;
5 printf("$ ");
6 while ( ( ( *help = getchar() ) != EOF ) &&
7 ( *help != '\n' )
8 ) help ++;
9
10 *help = (char )'\0';
11 return ( help == buf ? 0 : 1 );
12 }
13
14 int main(void) {
15 char cmd[1024];
16 while ( read_line(cmd) ) {
17 switch ( fork () ) {
18 case 0: execl(cmd, cmd,
19 (char *) 0);
20 exit(0);
21 case -1: perror("fork failed.");
22 exit(-1);
23 default: wait(NULL);
24 }
25 }
26 exit(0);
27 }
artemis Src 105 simple_shell $ /bin/ls hello hello.c simple_shell simple_shell.c $ /bin/date Mon Apr 7 18:17:32 MET DST 1997 $ who $ /bin/who bischof console Apr 7 15:17 bischof ttyp1 Apr 7 17:14 bischof ttyp3 Apr 7 17:44
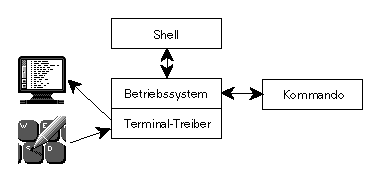
Normalerweise kann man voraustippen und auch eine Zeile noch korrigieren, bevor sie ein Prozeß sieht. Bestimmte Tasten haben dabei meistens eine besondere Bedeutung, die über das Kommando stty gesteuert werden kann. Um das zu verstehen, muß man sich das Modell des Terminal-Treibers klarmachen:
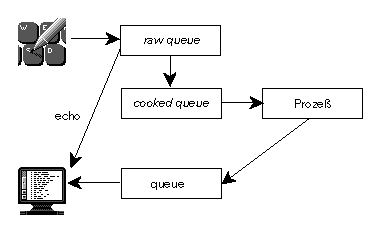
$ sleep 10; dd bs=1024 count=1 hp date hp 0+1 records in 0+1 records out $ date Thu Mar 20 18:36:28 MET 1997
$ { echo hpb
> echo date
> } | dd bs=1024 count=1
hpb
date
0+1 records in
0+1 records out
0 8 16 24 32 40 48 56 64 72 80 88 96 104 112 120
0 nul bs dle can leer ( 0 8 @ H P X ` h p x
1 soh ht dc1 em ! ) 1 9 AQ Y a i q y
2 stx nl dc2 sub " * 2 B : J R Z b j r z
3 etx vt dc3 esc # + 3 ; C K S [ c k s {
4 eot np dc4 fs $ , 4 < D L T \ d l t |
5 enq cr nak gs % - 5 = E M U ] e m u }
6 ack so syn rs & . 6 > F N V ^ f n v ~
7 bel si etb us ' / 7 ? G O W _ g o w del
------------------------------------------------------------------------------------------------
1 2 3 4 ... i ii iii iv ...
$ stty -crterase -crtbs # am NeXT $ stty erase X $ dudXXate Thu Apr 19 05:46:07 MEZ 1990
$ stty -crtkill # am NeXT $ stty kill Y $ dateY date Thu Apr 19 05:46:27 MEZ 1990
$ stty intr A $ dd A0+0 records in 0+0 records out $ dudeAdate Mon Apr 7 18:23:50 MET DST 1997
$ stty quit B $ dudeBdate Mon Apr 7 18:24:22 MET DST 1997
In diesem Bereich differieren die verschiedenen UNIX-Varianten sehr stark. Nach der SVID sollte folgendes gelten :
$ stty speed 9600 baud; -parity hupcl brkint -inpck -istrip icrnl onlcr cr0 nl0 tab3 bs0 vt0 ff0 echo echoe echok $ stty -a ...
$ stty -g d06:1805:4bd:3b:7f:3:8:15:4:0:0:0 $ stty sane
Ohne Argumente zeigt das Kommando stty die Einstellungen. Mit Argumenten ändert stty Einstellungen und kann durchaus ein Terminal unbrauchbar machen! Problematisch ist, daß stty sowohl die serielle Verbindung als auch die logische Verarbeitung im Treiber steuert.
-a everything alle aktuellen Einstellungen zeigen zahl Geschwindigkeit evenp oddp Parität cs7 -pass8 Anzahl Datenbits sane - relativ normale Werte erase x Zeichen löschen intr x abbrechen kill x Zeile löschen quit x abbrechen mit Speicherauszug echo Echo zum Schirm echoe crtbs erase mit bs darstellen echok -crtkill bei kill Zeilentrenner ausgeben lcase groß als klein ansehen nl nur ctl-j beendet Zeile tabs Tabulatorzeichen ausgeben icanon -cbreak zeilenweise Eingabe -icanon cbreak zeichenweise Eingabe min n - Anzahl Zeichen abzuwarten time n - Zeit abzuwarten raw jedes Zeichen geht sofort zum Programm, keine Signale
Bedingungen wie lcase kann man durch ein Minuszeichen davor umkehren. [Details: Literatur]
I. a. R. wird eine Terminal von einem anderen Terminal aus eingestellt.
Terminal ttyp0:
verdi bischof 111 PS1="`tty` " /dev/ttyp0 uname -a SunOS verdi 4.1.3_U1 5 sun4m /dev/ttyp0 stty -a | sed 2q speed 9600 baud; rows 10; columns 80; line = 2; intr = ^C; quit = ^; erase = ^?; kill = ^U; eof = ^D; eol = <undef>; $ echo "anderes Terminal ..." /dev/ttyp0 stty -a | sed 2q speed 9600 baud; rows 23; columns 80; line = 2; intr = ^C; quit = ^; erase = ^?; kill = ^U; eof = ^D; eol = <undef>;
Terminal ttyp3:
verdi bischof 111 PS1="`tty` " /dev/ttyp3 uname -a SunOS verdi 4.1.3_U1 5 sun4m /dev/ttyp3 stty rows 23 < /dev/ttyp0
Wenn man erst einmal Kommandos absetzen kann, kann man mit stty das Terminal zähmen. Damit das Terminal aber überhaupt Kommandos annimmt, muß man sich schon angemeldet haben. Der Systemstart geht etwa so vor sich:
Das Betriebssystem wird in den Speicher geladen, gestartet, und ein allererster Prozeß führt das Programm /etc/init aus.
Unter Sun OS 4.1.3 kontrollieren /etc/rc.boot, /etc/rc, /etc/rc.local welche Prozesse gestartet werden.
Unter Sun OS 5.x kontrollieren die Skripte in /etc/rc.d/* welche Prozess gestartet werden. Siehe auch inittab(4).
/etc/init startet nach Maßgabe einer Tabelle /etc/inittab oder /etc/ttys Prozesse für die Terminal-Geräte (oder -Simulationen), an denen eine Anmeldung erfolgen soll.
Jeder derartige Prozeß führt zuerst das Programm /etc/getty aus, das mit Hilfe seiner Argumente und einer Tabelle /etc/gettytab das Terminal einstellt. Speziell für Modems können dabei auch die Baud-Raten zyklisch gewechselt werden, bis eine Eingabe erkannt wird.
getty fordert den login-Namen an und führt dann im gleichen Prozeß das Programm /bin/login aus, das ein Paßwort abfragt.
Das Paßwort wird in der Datei /etc/passwd (oder /etc/shadow oder in der Trusted Computing Base oder bei der Netzdatenbank) verifiziert; anschließend startet login im gleichen Prozeß die Shell, die für den Benutzer vorgesehen ist, setzt den Heimatkatalog, usw.
Den Anfangszustand der Übertragungsparameter kontrolliert also getty.
Jeder Prozeß gehört zu einer Prozeßgruppe, die einen Anführer haben kann -- für ihn sind Prozeß- und Prozeßgruppennummer gleich.
Jede Prozeßgruppe enthält wenigstens einen Prozeß, der aber nicht unbedingt der Anführer sein muß.
Sessions gliedern Prozeßgruppen zur Verteilung von Signalen und zur Zugehörigkeit zu einem Kontroll-Terminal. Jeder Prozeß gehört zu einer Session. Jede Session enthält wenigstens eine Prozeßgruppe. Die Prozeßgruppen können in eine Vorder- und viele Hintergrundprozeßgruppen eingeteilt werden.
Eine Session kann maximal ein kontrollierendes Terminal haben. Der Session leader etabliert die Verbindung zum kontrollierenden Terminal, man nennt ihn dann auch controlling process.
Falls eine Session ein kontrollierendes Terminal hat, gehen am Terminal erzeugten Interrupts an die Prozesse der Vordergrundprozeßgruppe -- sprich Signale gehen vom Terminal-Treiber nur an die Vordergrund-Prozeßgruppe des Kontroll-Terminals.
Falls das Modem abgeschaltet wird, oder das Pseudoterminal stirbt, wird an den Session leader ein hangup-Signal geschickt. Der dieses Signal dann an die Mitglieder der Vordergrundprozeßgruppe weiter schickt.
Falls der Session leader stirbt, wird dieses Signal an alle Mitglieder der Vordergrundprozeßgruppe geschickt.
Man schützt Hintergrundprozesse durch Aufruf unter nohup.
Siehe auch Advanced Programming in the Unix Environment, W. Richard Stevens, Addison-Wesley, ISBN: 0-201-56317-7.
Übersicht
Nach X/OPEN und der SVID sind folgende Kommandos einigermaßen Standard:
Art Beispiele ------------------------------------------------------- Identifizieren login newgrp passwd Information cal date df du id logname man tty Kommunikation mail mesg news who write Vernetzung rlogin, tip etc. Systemverwaltung acct, crontab, dump, mount etc. Dateien chgrp chmod chown ln ls mv rm touch Kataloge find mkdir rmdir Kompaktieren pack pcat unpack Kopieren cp cpio dd tar tee Betrachten cat file od pg tail Anordnen pr sort uniq Untersuchen cmp comm diff egrep fgrep grep wc Text aendern csplit cut join paste split tr Service at calendar cancel lp lpstat stty Prozesse kill nice nohup ps time Rechnen basename dirname expr Programmieren env false sleep test true Subsysteme awk make sed sh vi
Die Klassifizierung ist nicht strikt. Manche Kommandos passen in mehrere Kategorien. Die Liste beinhaltet nicht:
Art Beispiele --------------------------------------------- Shell-interne Kommandos cd, echo, pwd etc. Programmiersysteme C, Fortran etc. Prozeßkommunikation ipcs, mkfifo etc.
Die folgenden Beschreibungen sind auf einigermaßen Nützliches reduziert. Die GNU-Implementierungen der Kommandos liefern in der Regel eine Gebrauchsanweisung, wenn das Argument --help angegeben wird.
Die Verweise in diesem Kapitel zeigen auf nützliche Manualseiten.
Login: (login)
$ login login: bischof Password: ...
Der Benutzername legt Benutzernummer und -gruppe fest. Der Name kann mit einem Paßwort gesichert sein. Als Datenbasis dient /etc/passwd und /etc/group bzw. NIS (ypcat).
Telnet: (telnet)
$ telnet cs.oswego.edu Trying 129.3.20.253... Connected to cs.oswego.edu. Escape character is '^]'. UNIX(r) System V Release 4.0 (altair) login: ... $ telnet 129.3.20.253 Trying 129.3.20.253... Connected to 129.3.20.253. ... $
Mit telnet kann man sich auf dem lokalen oder auf einem entfernten Rechner anmelden. Als Datenbasis für den login-Vorgang wird die Datenbasis aus /etc/passwd bzw. NIS. des entsprechenden Rechners verwendet.
telnet kann auch dazu verwendet werden einen Port auf einem Rechner anzusprechen. Siehe auch services(5)
$ telnet cs.oswego.edu 13 Trying 129.3.20.253... Connected to cs.oswego.edu. Escape character is '^]'. Mon Apr 21 08:08:22 1997 Connection closed by foreign host. $ telnet cs.oswego.edu 79 Trying 129.3.20.253... Connected to cs.oswego.edu. Escape character is '^]'. tymann Login Name TTY Idle When Where ltymann Lisa Tymann pts/8 <Mar 17 12:51> localhost tymann Paul Tymann term/a <Apr 21 06:27> Connection closed by foreign host. $ telnet cs.oswego.edu 21 Trying 129.3.20.253... Connected to cs.oswego.edu. Escape character is '^]'. help 220 altair FTP server (Version wu-2.4(2) Fri Jan 17 16:30:39 EST 1997) ready. 214-The following commands are recognized (* =>'s unimplemented). USER PORT STOR MSAM* RNTO NLST MKD CDUP PASS PASV APPE MRSQ* ABOR SITE XMKD XCUP ACCT* TYPE MLFL* MRCP* DELE SYST RMD STOU SMNT* STRU MAIL* ALLO CWD STAT XRMD SIZE REIN* MODE MSND* REST XCWD HELP PWD MDTM QUIT RETR MSOM* RNFR LIST NOOP XPWD 214 Direct comments to ftp-bugs@altair.
$ rsh thor -l nil Password: thor:[nil]# id uid=0(root) gid=1(daemon) groups=1(daemon),0(wheel) $ exit # zureuck zur vorherigen shell $ hostname artemis $ echo artemis > /home/bischof/.rhosts $ rsh thor date Wed Apr 16 09:44:09 MET DST 1997
Mit rsh bzw. rlogin kann man sich auf dem lokalen oder auf einem entfernten Rechner anmelden und gegebenenfalls ein Kommando ohne Angabe eines Paßworts absetzen. Die Dateien /$HOME/.rhosts bzw. /etc/hosts.equiv entscheiden welche Rechner als vertrauenswürdig anzusehen sind. Die Dateien werden nur zur Kontaktaufnahme konsultiert.
Großzügiges füllen einer der beiden Dateien ermöglicht ein leichtes einbrechen.
$ rm ~/.rhosts $ echo artemis > ~/.rhosts && rsh artos "rm -f ~/.rhosts; who" gremeyer console Apr 16 07:03 gremeyer ttyp1 Apr 16 07:03 gremeyer ttyp2 Apr 16 08:11 $ rsh portos Password:
Man kann verhindern, daß sich der Benutzer mit der UID 0 via rsh, rlogin oder telnet anmelden kann. Siehe auch ttytab(5)
Daten übertragen: (ftp)
ftp wird dazu verwendet Daten zu übertragen. Ftp-Server akzeptieren als Benutzerkennung i.a.R. ftp oder anonymous.
Durch Nutzung von netrc(5) kann man initial-Werte vorgaben.
$ ftp ftp.rz.Uni-Osnabrueck.DE Connected to ftp.rz.Uni-Osnabrueck.DE. 220 epimetheus FTP server (Version wu-2.4(8) Thu Jan 16 14:... Name (ftp.rz.Uni-Osnabrueck.DE:bischof): anonymous 331 Guest login ok, send your complete e-mail address as password. Password:
Die interessanten Daten finden sich i. a. R. im Katalog /pub.
ftp> pwd 257 "/pub/unix/gnu" is current directory. ftp> bin 200 Type set to I. ftp> get spell-1.0.tar.gz 200 PORT command successful. 150 Opening BINARY mode data connection for spell-1.0.tar.gz (44388 bytes). 226 Transfer complete. local: spell-1.0.tar.gz remote: spell-1.0.tar.gz 44388 bytes received in 0.06 seconds (6.7e+02 Kbytes/s)
Man kann ftp auch im Batch-Betrieb verwenden.
1 { echo open ftp.rz
2 echo user ftp bischof@
3 echo ls
4 echo bye
5 } | ftp -ni # 1 - Zeichen
6
Gruppe wechseln: (newgrp)
$ newgrp gruppe # In neue Gruppe wechseln. $ newgrp login-Gruppe
Wechselt in eine neue Benutzergruppe, falls erlaubt. Siehe auch /etc/group bzw. NIS (ypcat).
Dabei wird die Shell neu geladen. (In der Regel nur am Terminal möglich.) Funktioniert nicht bei Berkeley-Systemen, denn dort kann ein Benutzer in mehrere Gruppen eingetragen sein.
Passwort wechseln: (passwd)
$ passwd # Eigenes Paßwort ändern. Changing password for bischof. # (bei NIS-Verwaltung: yppasswd ) Old password: New password: Retype new password:
Trägt ein (neues) Paßwort ein. (In der Regel nur am Terminal möglich.)
Man kann sowohl Loginname wie auch die default-Shell modifizieren.
$ yppasswd -s Changing NIS login shell for bischof on thor. Old shell: /usr/local/gnu/bin/bash New shell: ^C $ yppasswd -f Changing NIS finger information for bischof on thor. Default values are printed inside of '[]'. To accept the default, type <return>. To have a blank entry, type the word 'none'. Name [Hans-Peter Bischof]: ^C
Information
``Ewiger'' Kalender: (cal)
$ cal # Kalender fuer aktuellen Monat ausgeben.
$ cal jahr # ganzes Jahr
$ cal monat jahr # bestimmter Monat
$ cal 9 1752
September 1752
S M Tu W Th F S
1 2 14 15 16
17 18 19 20 21 22 23
24 25 26 27 28 29 30
Datumsausgabe in vielen Variationen: (date)
$ date # +format Ausgabe a la printf formatieren. $ date Fri Apr 4 12:31:38 MET DST 1997 $ date '+%w/%y' 5/97 $ date '+%D' 04/18/97 $ date '+%A %B %Y' Friday April 1997
freier Plattenplatz: (df)
$ df Filesystem 1024-blocks Used Available Capacity Mounted on /dev/sd0a 1020893 411996 506807 45% / /dev/sd0b 1020894 756107 162697 82% /export $ df /dev/sd0a /dev/rsd0a Filesystem 1024-blocks Used Available Capacity Mounted on /dev/sd0a 1020893 411996 506807 45% / /dev/rsd0a 1020893 411996 506807 45% $ df -i Filesystem Inodes IUsed IFree %IUsed Mounted on /private/vm/swapfile 255360 27143 228217 11% /private/vm/swapfile.front portos:/export/local -1 0 -1 0% /tmp_mnt/Local /dev/sd0a 255360 27143 228217 11% /
Platzverbrauch: (du)
$ du -s . 131071 . $ du c.01 4 c.01 $ ls -l c.01 -rw-r--r-- 1 bischof inform 3828 Apr 3 18:23 c.01
Wer bin ich?: (id, who, logname)
$ id # login-Information ausgeben. $ id uid=106(bischof) gid=11(inform) groups=11(inform),0(wheel)... $ id -g 11 $ id -u 106 $ logname bischof $ who am i artemis!bischof ttyp1 Apr 17 15:56 $ who ss ss artemis!bischof ttyp1 Apr 17 15:56
Wie kommt man an die Information: (man)
$ man kommando # Manualseite ausgeben. $ man nummer kommando # aus bestimmtem Abschnitt $ man 1 ed $ man 2 read
Es ist darauf zu achen, daß die ``richtige'' Manual-Seite gefunden wird. Sprich $MANPATH und $PATH sollten übereinstimmend sein.
Elektronische Post: (mail)
$ mail # Eingegangene Post zeigen. $ mail benutzer # Brief schreiben. $ mail benutzer@rechner # an Benutzer an fremdem Rechner $ ... | mail ... # Text(!) verschicken.
Zum Betrachten der Post gibt es viele Kommandos, insbesondere ? für Instruktionen. Beim Schreiben eines Briefes kann man mit ~? am Zeilenanfang Instruktionen sehen. Es gibt mehr oder weniger komfortable Abarten von mail.
Man kann eine mail auch fälschen. Dies ist dann wohl Betrug.
$ telnet artemis 25 Trying 131.173.161.32... Connected to artemis. Escape character is '^]'. 220 artemis.informatik.uni-osnabrueck.de ESMTP HELO artemis 250 artemis.informatik.uni-osnabrueck.de Hello artemis [131.173.161.32], pleased to meet you MAIL From: <h_k@dbt.de> 250 <h_k@dbt.de>... Sender ok RCPT To: bischof 250 bischof... Recipient ok Data 354 Enter mail, end with "." on a line by itself Lieber HP, ich suche gerade einen ... -hk . 250 LAA09824 Message accepted for delivery QUIT 221 artemis.informatik.uni-osnabrueck.de closing connection Connection closed by foreign host. $ mail Mail version 8.1 6/6/93. Type ? for help. "/usr/spool/mail/bischof": 1 message 1 new >N 1 h_k@dbt.de Wed Apr 16 11:00 12/683 & Message 1: From h_k@dbt.de Wed Apr 16 11:00:53 1997 From: h_k@dbt.de Date: Wed, 16 Apr 1997 11:00:03 +0200 (MET DST) Hast Du nicht Lust mein neuer M ... zu werden? -hk
Direktkommunikation am Terminal: (mesg, talk)
$ mesg # Fremdzugriffsrechte auf eigenes Terminal zeigen. $ mesg y # erlauben $ mesg n # verbieten $ write user tty # kommunizieren falls die Zugriffsrechte stimmen $ talk bischof@artemis $ news # (Bei uns lokale) Neuigkeiten zeigen.
Es gibt eine ganze Subkultur news und entsprechend viele Programme zum Schreiben und Lesen von Artikeln. Leider ist der Informationsgehalt begrenzt.
Wer ist/war angemeldet: (who, last)
$ who bischof console Apr 4 08:21 bischof ttyp1 Apr 4 08:21 bischof ttyp2 Apr 4 08:24 $ last bischof ttyp5 Fri Apr 4 12:42 still logged in bischof ttyp4 Fri Apr 4 12:31 still logged in bischof ttyp6 Fri Apr 4 12:16 still logged in bischof ttyp5 Fri Apr 4 11:26 - 12:29 (01:03) bischof ttyp5 Fri Apr 4 09:37 - 09:37 (00:00) bischof console artemis ... reboot ~ Thu Apr 3 19:12 ... $ who /usr/adm/wtmp gremeyer ttyp3 Apr 1 07:36 (portos) bischof ttyp3 Apr 1 08:33 shutdown ~ Apr 3 10:09 shutdown ~ Apr 3 10:10 ... $ who am i artemis!bischof ttyp6 Apr 4 12:16 $ who i am artemis!bischof ttyp6 Apr 4 12:16 $ who bist Du artemis!bischof ttyp6 Apr 4 12:16
Bei der Anmeldung erhält man eine Benutzer- und Gruppennummer. Wenn ein neues Objekt im Dateisystem angelegt wird, erhält es diese als Besitzer- und Gruppennummer. Zugriff auf das Objekt wird durch die Rechte
festgelegt. Wobei dies in die Kategorien Besitzer, Besitzer-Gruppe, Rest der Welt eingeteilt ist.
Die Ausführrechte bei Katalogen bedeutet, daß man einen Suchzugriff bekommt.
Zugriffsrechte ändern: (chmod, chown, chgrp)
$ chgrp gruppe pfad... # Besitzer-Gruppe ändern. $ chown besitzer pfad... # Besitzer ändern. $ chmod +x pfad... # Ausführung erlauben. $ chmod -w pfad... # Schreiben verbieten.
Diese Änderungen darf nur der Besitzer (oder der Super-User) vornehmen. chmod akzeptiert die Rechte oktal (640 erlaubt Lesen für Besitzer und Gruppe, Schreiben für Besitzer) oder als Formel, wobei mehrere Operationen durch Komma getrennt werden:
u für Besitzer, g für Gruppe, o für Rest
mit + - = kann man Rechte hinzufügen, wegnehmen, absolut einstellen:
Mit u+s oder 4000 definiert man, daß bei Ausführung eines binären Programms temporär die Besitzernummer der Datei als effektive Benutzernummer des Prozesses verwendet wird, (setuid(3)) die den Zugriff auf Dateien regelt. Analog führt g+s oder 2000 die Gruppennummer der Datei als effektive Gruppennummer ein. Damit kann zum Beispiel ein normaler Benutzer für genau kontrollierte Operationen die Rechte des Super-Users erhalten.
Wie könnte man sonst drucken?
Analog führt +t oder 1000 dassticky-Bit ein. Dies bedeutet, falls
Wie könnte man sonst vernünftig mit einer tmp arbeiten?
Die Verwendung des sticky-Bit kann zu einer effizienteren Nutzung der Ressourcen führen.
Src ## 9 ls -ld Sticky sticky drwxr-xr-x 2 root inform 1024 Apr 23 08:55 Sticky -rwxr-xr-x 1 bischof inform 24576 Apr 23 08:50 sticky verdi Src ## 10 chmod +t Sticky verdi Src ## 11 ls -ld Sticky drwxr-xr-t 2 root inform 1024 Apr 23 08:55 Sticky verdi Src ## 12 chmod 1755 sticky verdi Src ## 13 ls -l sticky -rwxr-xr-t 1 bischof inform 24576 Apr 23 08:50 sticky
Eine Datei, viele Namen: (ln)
$ ln alteDatei neuerName # Einer Datei einen weiteren Namen geben. $ ln alteDatei... katalog # mehrere Dateien in einem Katalog $ ls -l orig -rw-r--r-- 1 bischof inform 0 Apr 16 11:04 orig $ ln orig orig.ln $ ls -li orig orig.ln 14639 -rw-r--r-- 2 bischof inform 0 Apr 16 11:04 orig 14639 -rw-r--r-- 2 bischof inform 0 Apr 16 11:04 orig.ln $ rm orig $ ls -li orig.ln 14639 -rw-r--r-- 1 bischof inform 0 Apr 16 11:04 orig.ln
Diese mehrfache Benennung ist nur im gleichen Dateisystem möglich. Bei vielen Systemen kann man symbolische Links eintragen:
$ ln -s ersatzPfad ziel # Verweis auf andere Datei eintragen.
Mehrfache Benennung von Katalogen ist nur mit symbolischen Links erlaubt. Dies kann zu Dateisystemen führen, die sehr verwirrend sind.
$ ln -s / root $ ls -l root lrwxrwxrwx 1 bischof inform 1 Apr 16 11:12 root -> / $ ls -L root | sed 1q artemis_sd0a $ cd root $ pwd /export/home/bischof/Vorlesung/Sp_97/Skript/root $ /bin/pwd /
Mir der Option -f kann der super user einen harten Link zwischen Katalogen erzwingen. Davon ist abzuraten.
Fifo: (mknod)
Es gibt unter Unix folgende Dateitypen/Geräte
Blockgeräte Magnetband, Platte Charactergeräte Platte, Terminal Datei Fifo, reguläre Dateien, Sockets, Links, symbolische Links Katalog
$ mkfifo FIFO $ ls -l FIFO prw-r--r-- 1 bischof inform 0 Apr 18 14:28 FIFO $ echo `date` > FIFO & [1] 17064 $ ls -l FIFO prw-r--r-- 1 bischof inform 0 Apr 18 14:28 FIFO $ cat FIFO Fri Apr 18 14:29:02 MET DST 1997 [1]+ Done echo `date` >FIFO $
Dies kann nicht über Rechnerkanten hinweg funktionieren, weil die Synchronisatzion innerhalb des Kerns geregelt wird.
Datei-Listing: (ls)
$ ls -option pfad... # Dateinamen und Informationen zeigen.
Es gibt sehr viele, kombinierbare Optionen, zum Beispiel:
-a auch Dateinamen mit Punkt am Anfang -d Katalog zeigen, nicht seinen Inhalt -i mit inode-Zahl -l mit langer Information -r rückwärts sortiert -R rekursiv durch Unterkataloge -s mit Größe (in 512-Byte Blöcken) -t nach Schreibzeit sortiert -ut nach Zugriffszeit sortiert
Umbenennen: (mv)
Eine Datei wird im gleichen Dateisystem durch einen Aufrufe von mv umbenannt. Andernfalls muß sie kopiert und gelöscht werden; dabei gehen aber Links verloren.
$ mv alteDatei neuerName # Einer Datei einen anderen Namen geben. $ mv alteDatei... katalog # mehrere Dateien in einem Katalog
Löschen: (rm)
$ rm datei... # Dateien löschen. $ rm -f datei... # ohne Rückfrage $ rm -i datei... # im Dialog $ rm -r pfad... # rekursiv
Wenn der letzte Link gelöscht wird, wird der Platz der Datei wieder verfügbar.
Zeitstempel aktualisieren: (touch)
$ touch pfad... # Zeitstempel neu setzen. $ touch mmddhhmmyy pfad... # explizit $ touch -c pfad... # falls nicht-existent, nicht erzeugen
touch liest und schreibt das erste Zeichen der Datei, sonst würde sich über NFS nichts ändern.
Es gibt Probleme, wenn das Dateisystem via NFS von NeXTStep auf SunOS 4.1.3 montiert wird.
SunOS mozart 4.1.3_U1 1 sun4m echo xx > to_old_to_rock SunOS mozart 4.1.3_U1 1 sun4m ls -l to_old_to_rock -rw-r--r-- 1 bischof inform 3 Apr 18 14:34 to_old_to_rock SunOS mozart 4.1.3_U1 1 sun4m touch to_old_to_rock SunOS mozart 4.1.3_U1 1 sun4m ls -l to_old_to_rock -rw-r--r-- 1 bischof inform 3 Jan 1 1970 to_old_to_rock
Dateisystem traversieren: (find)
$ find pfad... bedingung... -o bedingung...
find traversiert Katalogbäume und verknüpft alle Dateinamen mit den Bedingungen.
Bedingungen sind UND-verknüpft, können mit ! negiert, mit -o ODER-verknüpft und mit \( \) geklammert werden. Je nach Version von find gibt es sehr viele Bedingungen, zum Beispiel:
-print aktuellen Pfad ausgeben; immer wahr
-atime -5 Zugriff seit weniger als 5 Tagen?
-exec ls -l {} \; Kommando für aktuellen Pfad erfolgreich?
-name muster paßt Dateiname?
-newer datei später geändert als die Datei?
-size 0 leer?
-type d ist es Katalog?
-user name richtiger Besitzer?
$ cd /home/bischof/X
$ find a b -type d -print -exec ls -l {} \;
$ find a b -type d -print -exec ls -l {} \;
a
total 0
-rw-r--r-- 1 bischof inform 0 Apr 4 16:13 in_a
b
total 0
-rw-r--r-- 1 bischof inform 0 Apr 4 16:13 in_b
-name wendet ein Muster nur auf die aktuelle Pfadkomponente an. Wenn man ganze Pfade untersuchen will, muß man eine Kombination von du -a und grep verwenden.
$ touch an aber $ find . -name a* find: paths must precede expression Usage: find [path...] [expression] $ find . -name 'a*' -print ./an ./aber
Kataloge erzeugen/löschen: (mkdir, rmdir)
$ mkdir katalog... # Leere Kataloge erzeugen. $ rmdir katalog... # Leere Kataloge löschen.
Kataloge samt Inhalt kann man mit rm -rf sehr radikal entfernen.
Kompaktieren: (compress)
$ compress datei... # Dateien kompaktieren. $ uncompress datei.Z # Kompaktierte Datei wiederherstellen.
Es gibt verschiedene derartige Familien, zum Beispiel GNU Hier spielt die Furcht vor Software-Patenten eine große Rolle.
Bereits kompaktierte Dateien sollte man nicht nochmals kompaktieren. Manche Kommunikationsprogramme kompaktieren selbst, oder sie können nicht mit 8-Bit Information umgehen.
Crypt: (crypt)
Es gibt die Möglichkeit Dateien verschlüsselt abzulegen.
$ echo 'Hoho' > ho $ cat ho | crypt bg > ho.crypt $ od -c ho.crypt 0000000 037 205 A 234 0 0000005 $ $ cat ho.crypt | crypt bg Hoho
Kopieren von Dateien (cp)
$ cp alteDatei neueDatei # Eine Datei kopieren. $ cp alteDatei... katalog # mehrere Dateien in einen Katalog
Kopieren von Bäumen (cpio, tar)
$ ls | cpio -oc > /tmp/cpio.out # Dateien archivieren. $ cpio -ict < /tmp/cpio.out # I.-V. eines Archivs zeigen. $ cpio -icdum < /tmp/cpio.out # Archiv einspielen. $ cd alt; \ # Dateibaum als Links kopieren. > find . -depth -print | cpio -pdl neuerPfad $ tar cf /tmp/x Soelim $ tar cf - Soelim | ( cd /tmp && tar xf - ) $ ls -ld /tmp/S* drwxr-xr-x 2 bischof wheel 1024 Apr 4 15:19 /tmp/Soelim $ tar cf - Soelim | ( cd /tmp; tar xf - ) tar cf tar.out pfad... # Dateien und Bäume archivieren. $ tar tf tar.out # Inhaltsverzeichnis eines Archivs zeigen. $ tar xf tar.out muster... # Archiv einspielen. $ ( cd alt && tar cf -. ) | \ # Dateibaum kopieren. > ( cd neu && tar xf - )
Archive mit absoluten Pfaden sind nicht sehr praktisch.
Datenstrom byteweise betrachten: (dd)
$ dd < ein > aus bs=30k # Kopieren.
dd kopiert, wobei fixe Satzlängen und Anzahl von Sätzen kontrolliert werden können. Es gibt viele Optionen mit einer sehr veralteten Syntax, zum Beispiel:
bs=10k in Stücken von 10 KB skip=6 zuerst 6 10KB-Blöcke überspringen seek=8 zuerst 8 10KB-Blöcke in Ausgabe überspringen count=20 bis zu 20 10KB-Blöcke kopieren conv=sync Ausgabe ist Vielfaches von 10KBdd ist das einzige Programm, das aus binärer Information nach Position Bytes extrahieren kann.
hello.c:
1 void main(void){ printf("hello\n"); exit(0); }
$ make hello cc hello.c -o hello $ hello hello $ strings -o hello 8060 The kernel support for the dynamic linker is not present to run this program. 8140 __dyld_make_delayed_module_initializer_calls 8185 hello $ dd bs=1 if=hello of=x count=5 skip=8185 5+0 records in 5+0 records out $ cat x hello $ dd bs=1 if=hello of=1 count=8185 8185+0 records in 8185+0 records out $ echo HELO > 2 $ dd bs=1 if=hello of=3 skip=8190 23390+0 records in 23390+0 records out $ cat 1 2 3 > x $ chmod +x x $ x HELO
Spionieren innerhalb einer Pipe: (tee)
$ ... | tee datei... |... # Eingabe in alle Dateien und zur Ausgabe kopieren. $ ... | tee -a datei... |... # anhängen
Cat: (cat)
$ cat datei... # Dateien zu Terminal kopieren. $ cat > datei # Terminal in Datei $ cat >> datei # an Datei anhängen $ cat datei... > ausgabe # Dateien in Datei $ cat << 'ende' # Text zu Terminal hier ist text ende $ cat eins - zwei | mail Datei/Terminal in Pipe
cat bearbeitet (wie jedes sogenannte Filter-Programm) seine Standard-Eingabe oder Dateien, deren Namen als Argumente angegeben sind, und schreibt nur zur Standard-Ausgabe. Die eigentliche Leistung entsteht durch E/A-Umlenkung.
Art einer Datei: (file)
file errät(!) die Art des Dateiinhalts, siehe auch magic(5). text, executable, directory sind hierbei interessante Worte.
$ file pfad... # Datei klassifizieren. $ file . .: directory $ file /dev/tty /dev/tty: character special (2/0) $ file /dev/sd0a /dev/sd0a: block special (6/0) $ file /dev/rsd0a /dev/rsd0a: character special (14/0) $ file mk_gen mk_gen: executable shell script $ file Src/hello Src/hello: Mach-O executable (for architecture i386)
Betrachten von binären Daten: (od)
$ ... | od # Eingabe 16-Bit oktal darstellen. $ od datei # eine(!) Datei $ od datei +100. # ab dezimaler Position $ od -b datei # 8-Bit oktal $ od -c datei # Zeichen sichtbar $ od -d datei # 16-Bit dezimal $ od -x datei # 16-Bit hexadezimal
Betrachten einer Platte:
rc ## 15 od -c /dev/root | more 0000000 S U N 0 4 2 4 c y l ... 0000020 a l t 2 h d 9 ... 0000040 8 0 \0 \0 \0 \0 \0 \0 \0 \0 \0 ... 0000060 \0 \0 \0 \0 \0 \0 \0 \0 \0 \0 \0 ... * 0000640 \0 \0 \0 \0 021 0 \t 304 \0 \0 \0 ... \&... 0016240 B o o t b l o c k \0 c ... 0016260 u m % x ! = % x ... ...
Enden und Wenden: (tail)
$ ... | tail # Ende einer Texteingabe zeigen. $ tail -24 datei # letzte 24 Zeilen $ tail +1 datei # ab erster Zeile $ tail -f logbuch # Ende verfolgen
Seitenweises paginieren: (pr)
$ pr option... datei... ... # Text seitenweise anordnen.
pr kann auch mehrspaltig anordnen und Tabulatorzeichen entfernen oder erzeugen. Es gibt viele Optionen, zum Beispiel:
-zahl mehrspaltig, vertikal gefüllt -a ...aber horizontal gefüllt -e Tabulatorzeichen expandieren -f formfeed statt vielen Leerzeilen -h titel Seitentitel -i Tabulatorzeichen einfügen (Vorsicht) -l72 Seitenlänge -m Dateien mehrspaltig -n Zeilen numeriert -t kein Seitentitel und Abstand -w120 Zeilenlänge
$ cat 3.pr_ex
1
2 3 4 9
6 7 9
1
$ pr -l 1 -n -2 3.pr_ex
1 1 2 2 3 4 9
3 6 7 9 4 1
$ pr -l 1 -h 3.pr_ex -n -2 3.pr_ex | sed 2q
1 1 2 2 3 4 9
3 6 7 9 4 1
$ pr -h 3.pr_ex -n -2 3.pr_ex | sed 3q
$ pr -h 3.pr_ex -n -2 3.pr_ex | sed 3q
Apr 23 09:09 1997 3.pr_ex Page 1
Sortieren: (sort)
$ sort option... datei... # Textzeilen sortieren.
sort kann nach mehrfachen Kriterien in beliebiger Folge sortieren. Es gibt viele Optionen, zum Beispiel:
+zahl beginnend nach Zwischenraum (ab 0) -zahl endend vor Zwischenraum (ab 1) -d nur Buchstaben, Ziffern, Zwischenraum -f große und kleine Buchstaben gleich -n numerisch (Gleitpunkt) -o ausgabe Ausgabedatei (kann Eingabe sein) -r rückwärts -t: Zeichen : bedeutet den Zwischenraum -u nur eine Kopie pro Zeile ausgeben
$ cat 3.sort xaz:a:h aaz:d:h aac:g:j xyz:a:g abc:b:i 1:2:3 $ sort -t: +2 3.sort 1:2:3 xyz:a:g aaz:d:h xaz:a:h abc:b:i aac:g:j $ sort -t: +2 +1 3.sort 1:2:3 xyz:a:g xaz:a:h aaz:d:h abc:b:i aac:g:j $ sort +0.1 -0.2 3.sort 1:2:3 aac:g:j aaz:d:h xaz:a:h abc:b:i xyz:a:g
Uniq: (uniq)
$ ... | uniq # Duplikate bei Ausgabe unterdrücken. $ uniq datei # Datei $ uniq -c eingabe ausgabe # Anzahl notieren
Läßt man Anzahl (vor Zeile) ausgeben, kann man nach Häufigkeit sortieren.
$ cat 3.uniq
111
111
222
x11
x11
x22
x33
$ uniq -c 3.uniq
2 111
1 222
2 x11
1 x22
1 x33
$ uniq 3.uniq
111
222
x11
x22
x33
$ uniq -d 3.uniq
111
x11
Vergleichen und Unterschiede: (cmp, comm)
$ cmp eins zwei # Beliebige Information vergleichen. $ ... | cmp - zwei $ comm -123 eins zwei # Sortierten Text in Spalten anordnen. $ ... | comm -123 - zwei
comm ordnet sortierte Textzeilen in drei Spalten an: Zeilen nur in erster Datei, nur in zweiter und Zeilen in beiden. Die Option verhindert die Ausgabe der angegebenen Spalten.
Unterschiede in Text-Dateien: (diff)
$ diff eins zwei # Unterschied von Textdateien beschreiben. $ ... | diff - zwei
diff ist ein sehr effizienter Baustein, zum Beispiel für Versionskontrolle und zur Verteilung von Korrekturen für patch.
Man kann diff und ed dazu verwenden zwei Dateien in Übereinstimung zu bringen.
$ cat 1
111111111
$ cat 2
22222222
22222222
$ diff -e 1 2
1c
22222222
22222222
$ { diff -e 1 2 ; echo w; echo q } | ed - 1
$ cat 1
22222222
22222222
$ cp 2 1 # geht schneller, ist aber nicht selektiv
I. a. R. ist es günstiger Patches, und nicht ganze Dateien zu verschicken.
NeXT:/usr/bin/opendiff startet eine grafische Oberfläche für ein Programm wie diff
Pattern finden in Dateien: ([ef]?grep)
$ grep 'muster' datei... # Textzeilen nach Muster auswählen. $ egrep 'emuster' datei... # aufwendigere Muster,
Alternativen die schneller sind:
$ ... | fgrep 'text' # exakter Text,
Bei egrep und fgrep können Alternativen zeilenweise oder in einer Datei stehen, die nach -f angegeben wird. -l gibt nur Liste von Dateinamen mit Treffern aus. -v gibt nur Zeilen aus, die nicht passen.
Worte, Zeile und Zeichen zählen: (wc)
$ wc -clw datei... # Zeichen,
Die Optionen kontrollieren die Ausgabe; normalerweise alle drei Zahlen.
Zersplitten: (csplit)
$ csplit datei '/muster/+3'... # dritte Zeile nach Muster
$ csplit -k datei 100 {20} # bis zu 21 mal 100 Zeilen
csplit zerlegt eine Textdatei; die Stücke heißen xx00, xx01, usw. muster oder eine Zeilennummer legt den Anfang der zweiten,... Datei fest. {20} wiederholt das Muster oder die Zeilennummer als Anzahl Zeilen.
Senkrecht zerschneiden: (cut)
$ cut -c1-5,8-10,13- datei # nach Zeichenpositionen $ ... | cut -f3- -d: # : trennt Felder
cut gibt Ausschnitte von Textzeilen aus. Felder sind normalerweise durch Tabulatorzeichen getrennt.
Zusammenfügen: (join)
join hängt sortierte Textzeilen bei gleichem ersten Feld aneinander. Mit Optionen kann man beliebige Felder prüfen und in beliebiger Reihenfolge ausgeben.
$ cat 3.join a%a:first line b%a:second line c%a:third line $ $ cat 3.join.b a%b:first line b%b:second line d%b:third line $ join -t% 3.join 3.join.b a%a:first line%b:first line b%a:second line%b:second line $ join -t% -o1.2 2.2 3.join 3.join.b a:first line%b:first line a:second line%b:second line $ join -t% -o1.2 2.1 3.join 3.join.b a:first line%a a:second line%b
Zusammenfügen: (paste)
$ paste datei... # Dateien mit Tabulatorzeichen
$ ... | paste -d: datei -... # Datei und Eingabe mit :
$ ... | paste - - # Eingabe zweispaltig
$ paste -s -d'\t\n' datei # sukzessive Zeilen, je
# zwei mit Tabulatorzeichen
paste hängt positionsgleiche Zeilen aus verschiedenen Dateien aneinander. Die Zeichenliste bei -d dient dabei zirkulär als Trenner, aber am Schluß ist immer ein Zeilentrenner.
$ paste -d'^' 3.p* a%a:first line^a%b:first line^1 b%a:second line^b%b:second line^2 3 4 9 c%a:third line^c%b:third line^6 7 9 ^^1 $ paste -d'^' 3.paste 3.paste.b a%a:first line^a%b:first line b%a:second line^b%b:second line c%a:third line^c%b:third line $ paste -d'-----' 3.paste 3.paste.b a%a:first line-a%b:first line b%a:second line-b%b:second line c%a:third line-c%b:third line
Zerlegen: (split)
$ split -100 datei # je 100 Zeilen
split zerlegt eine Textdatei in Stücke xab, xab, usw. mit je gleich vielen Zeilen.
Zeichen ersetzen: (tr)
$ tr '[A-Z]' '[a-z]' <ein >aus # groß in klein $ tr -d '\15\32' <ein >aus # löschen: return und control-Z $ tr -cs '[A-Z][a-z]' '[\12*]' # ein Wort pro Zeile $ tr -cs '[A-Z][a-z]' '\12' # ein Wort pro Zeile [Berkeley]
tr ersetzt einzelne Zeichen: Zeichen in erstem Argument durch Zeichen in gleicher Position in zweitem Argument.
-c komplementiert erstes Argument, -d löscht statt zu ersetzen, -s gibt vielfache Zeichen im zweiten Argument nur einmal aus.
Aktivitäten zu einem bestimmten Zeitpunkt starten: (at)
$ at 1:00 # Auftrag für Uhrzeit (und Datum) hinterlegen.
sort -o bigfile bigfile
^D
$ at -l # Aufträge zeigen.
$ at -r auftrag... # löschen
$ tty
/dev/ttyp0
$ at 11:00
at> date > /dev/ttyp0
at> <EOT>
job 2914 at Sun Apr 6 11:00:00 1997
$ at -l
2914 a Sun Apr 6 11:00:00 1997
$ Sun Apr 6 11:00:01 MET DST 1997
Erinnerungsservice: (calendar)
$ calendar Calendar: Could not find calendar file in current directory $ # create calendar $ cat calendar April 17 Am Donnerstag donnerts April 18 Am Freitag ist frei und April 19 am Samstag kommt das Sams April 20 Am Sonntag scheint die Sonne ... April 21 Am Montag scheint der Mond $ calendar April 18 Am Freitag ist frei und April 19 am Samstag kommt das Sams April 20 Am Sonntag scheint die Sonne ... April 21 Am Montag scheint der Mond
calendar sucht Zeilen mit dem heutigen oder morgigen Datum in einer Datei $HOME/.calendar und gibt sie aus. Kennt Wochenende und manche Feiertage. Wird oft bei Nacht über alle Heimatkataloge als Systemservice angeboten.
Prozesse beenden: (kill)
$ kill prozessnummer... # SIGTERM Signal $ kill -9 prozessnummer... # SIGKILL Signal (sehr brutal) $ kill 0 # SIGTERM an Prozessgruppe
kill schickt ein Signal an Prozesse. Normalerweise verenden sie dann.
Prioritäten ändern: (nice)
$ nice kommando & # Kommando mit weniger Priorität ausführen. $ nohup kommando & # Kommando gegen Abbruch bei Abmelden schützen.
Beim Abmelden geht das Signal SIGHUP an alle eigenen Prozesse. Wir ein Prozeß mit nohup gestartet, bleibt der Prozeß aktiv und die Ausgabe findet sich in nohup.out.
Prozesszustände und Rechnerzustand: (ps, vmstat)
$ ps ps PID TT STAT TIME COMMAND 1200 p1 SW 0:00 -bash (bash) 14698 p1 S 0:00 rlogin verdi 14699 p1 S 0:00 rlogin verdi
ps zeigt Information über Prozesse. Damit erfährt man die Prozeßnummer für kill. Viele Optionen sind möglich.
vmstat, ps zeigt Information über das System. Damit erfährt man etwas über Auslastung des Systems, wie z.B. Swapping, ...
Ressourcebenutzung: (time)
$ time kommando # Laufzeiten eines Kommandos zeigen.
$ time test_links
19.2 real 7.5 user 4.1 sys
Vor allem die Verweilzeit kann variieren.
Pfadbetrachtung: (basename, dirname)
$ basename pfad # Letzte Pfadkomponente ausgeben. $ basename pfad endung # ohne Endung $ dirname pfad # Pfad ohne letzte Komponente ausgeben. $ basename /home/bischof/Vorlesung/Sp Sp $ dirname /home/bischof/Vorlesung/Sp /home/bischof/Vorlesung $ basename /home/bischof/Vorlesung/Sp/c01.ms .ms c01
Rechnen: (expr)
$ expr \( 3 + 4 \) \* 2 # Arithmetik 14 $ expr Abc \< abc # Vergleiche 1 $ expr aababccaa : aab # Mustervergleich 3 $ expr /dir/name : '.*/\(.*\)' # Extrakt: basename name $ expr /dir/na/me : '\(.*\)/[^/]*$' /dir/na
Diese Kommandos werden in der Regel im Zusammenhang mit Shell-Variablen oder in Kontrollstrukturen verwendet.
Environment: (env)
$ env # Exportierte Variablen zeigen. $ env - kommando # ohne Export $ env name=wert... kommando # zusätzliche Definitionen
Exitcodes: ($?)
$ false Bedingung, immer falsch. $ echo $? 255 $ true immer wahr $ echo $? 0 $ cat xx cat: xx: No such file or directory $ echo $? 1 $ grep XXXXX c.01 $ echo $? 1 $ grep x c.01 > /dev/null $ echo $? 0 $ grep "[ss" c.01 > /dev/null grep: RE error $ echo $? 2
Bedingungen: (test)
$ cd /usr/bin $ ls -li test [ 5609 -rwxr-xr-x 2 root 5200 Jan 21 1994 [ 5609 -rwxr-xr-x 2 root 5200 Jan 21 1994 test $ test bedingung # Bedingung prüfen. $ [ bedingung ] $ if [ -f c.01 ] > then > echo c.01 existiert > else > echo haeh > fi c.01 existiert
test ist meist eingebaut in der Shell. Bedingungen können mit -a UND-verknüpft, mit -o ODER-verknüpft, mit \( \) geklammert und mit ! negiert werden. Es gibt viele Terme, zum Beispiel:
-d datei existenter Katalog -f datei existente, normale Datei -s datei existente, nicht leere Datei -r datei lesbar -w datei schreibbar -x datei ausführbar -t Standard-Ausgabe ist Terminal "$var" Ersatztext nicht leer -z "$var" Ersatztext leer "$var" = text Strings gleich "$var" -le 10 numerisch kleiner-gleich
Eine Datei ist eine Informationsmenge, bei UNIX ohne innere Struktur, logisch also ein Vektor von Bytes (Zeichen). Sie erlaubt die Operationen Lesen, Schreiben, Positionieren in Einheiten von Bytes.
Typische Geräte erlauben beinahe das Vektor-Modell mit Lesen, Schreiben, Positionieren einzelner Bytes.
Ein Terminal kann nicht in der Informationsmenge positionieren und transferiert jeweils eine Zeile bzw. ein Zeichen.
Eine Platte kann durch Simulation mit Pufferung im Betriebssystem auf einzelne Bytes positionieren. Sie transferiert beliebige Vielfache ihrer Sektorlänge und durch Simulation mit Pufferung im Betriebssystem auch eine beliebige Anzahl von Bytes. Siehe auch sd.
Ein Magnetband kann nur bedingt, nämlich auf Dateimarken und Sätze, positionieren. Es kann oft nur Sätze mit einer geraden Anzahl von Bytes transferieren. Siehe auch st.
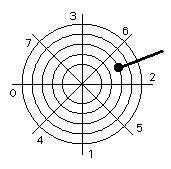
Platten haben konzentrische Spuren, die aus Sektoren bestehen. Nur Sektoren sind les- und schreibbar. Die Anordnung der Sektoren erfolgt beim Formatieren. Sie muß nicht sequentiell sein (interleaving). Sie muß auch auf benachbarten Spuren nicht gleich sein.
Eine Plattenadresse besteht aus Spur, Kopf, und Sektor. Bei gleicher Spur spricht man von Zylindern 1 Umschaltung zwischen Köpfen ist schnell.
Positional latency ist die Zeit, bis der Kopf auf der richtigen Spur steht. Sie besteht aus einer Anfahr- und Stop-Zeit sowie aus der Fahrzeit, die proportional zur Anzahl Spuren ist.
Rotational latency ist die Zeit, bis der gewünschte Sektor am Kopf erscheint. Sie kann durch interleaving bei sequentiellem Zugriff verkürzt werden.
Mittlere Zugriffszeit ist die Summe aus Positionierung über die halbe Platte und Sektorzahl. Typisch sind 100 Millisekunden für Floppies und 50 Millisekunden für (langsame) PC -Platten. Gut sind etwa 6 - 10 Millisekunden im UNIX-PC -Bereich. Sie kann durch geschickte Anordnung der Information auf der Platte unterschritten werden.
Transferrate mißt die Übertragung von Bytes zwischen Rechner und Platte, nachdem richtig positioniert wurde. Sie kann durch Zylinderzufgriff drastisch verbessert werden.
Je nach Einsatz der Platte sind andere Kenndaten besonders wichtig 1 für Dateien braucht man kurze Zugriffszeiten, für die Verdrängung von Prozessen swapping oder eine Datenbank kann eine hohe Transferrate wichtig sein.
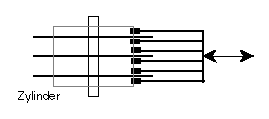
Eine Platte wird nach Spur, Kopf und Sektor adressiert. Eine Datei ist ein reservierter Bereich der Platte.
Die Plattenverwaltung ist dadurch recht einfach, der Nutzen einer Datei ist aber gering. Programme können sehr schnell geladen werden, Daten können direkt adressiert werden.
Die Plattenverwaltung ist komplizierter, aber eine Datei kann (je nach Adreßmanagement) beliebig wachsen. Daten können nur über Adreßtabellen adressiert werden.
Sektoren sind typischerweise 256 oder 512 Bytes, Blöcke sind typischerweise 512 oder 1024 Bytes. Berkeley's fast file system verwendet Blöcke mit 4K oder 8K und legt die abschließenden Stücke mehrerer Dateien in einen gemeinsam genutzten Block (fragment).
Ein Dateiname muß die Adressen aller Blöcke der Datei zugänglich machen.
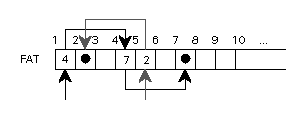
Freie Liste und lineares Dateisystem beschreiben die gesamte Fläche der Platte. Dateinamen im linearen Dateisystem entsprechen eindeutigen Flächen der Platte. Alle Dateinamen bilden einen einzigen Adreßraum.
/* Inode structure as it appears on a disk block. */
struct dinode
{
ushort di_mode; /* mode and type of file */
short di_nlink; /* number of links to file */
ushort di_uid; /* owner's user id */
ushort di_gid; /* owner's group id */
off_t di_size; /* number of bytes in file */
char di_addr[40]; /* disk block addresses */
time_t di_atime; /* time last accessed */
time_t di_mtime; /* time last modified */
time_t di_ctime; /* time inode changed */
};
/*
* the 40 address bytes:
* 39 used; 13 addresses
* of 3 bytes each.
*/
Das lineare Dateisystem kann Kataloge enthalten, das heißt Dateien, die dann ihrerseits Dateinamen enthalten, die auf das lineare Dateisystem verweisen.
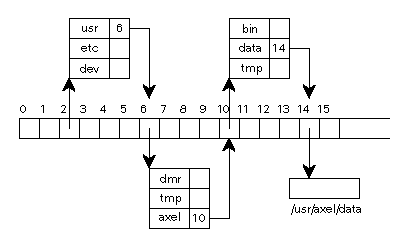
Bei Katalogen ist dieAnzahl der Verweise immer wenigstens 2 plus die Anzahl der Unterkataloge, denn ein Katalog zeigt mit dem Eintrag . auf sich selbst und mit .. auf seinen Vorgänger im Baum.
Hat man alle Dateien, kennt man den Freiraum auf der Platte als Komplement der Dateien.
UNIX verwendet heute eine zweite Schicht zwischen den Anforderungen von Benutzerprozessen und der Realisierung von Dateisystemen auf Platten. In dieser Schicht wird festgehalten, welche Server-Funktionen für die Manipulationen eines Dateisystems zuständig sind.
Inodes sind eine mögliche Implementierung eines Dateisystems. NFS-Service zu einem UNIX- oder gar DOS-System ist eine andere.
Das proc-Dateisystem beschreibt Informationen über Prozesse in Form eines Dateisystems, das sich dynamisch ändert. Damit lassen sich eine Reihe von Dienstprogrammen sehr elegant portabel implementieren. Auf LINUX kann man folgendes beobachten:
$ cd /proc; ls 1/ 29/ 37/ 44/ 510/ meminfo stat 1013/ 31/ 41/ 45/ kcore modules uptime 139/ 33/ 42/ 46/ kmsg net/ version 16/ 35/ 43/ 509/ loadavg self/ $ ls -l self total 3 -r--r--r-- 1 bischof root 0 Apr 18 07:58 cmdline lrwx------ 1 bischof root 64 Apr 18 07:58 cwd -> [0001]:1 -r--r--r-- 1 bischof root 0 Apr 18 07:58 environ lrwx------ 1 bischof root 64 Apr 18 07:58 exe -> [0305]:18450 dr-x------ 2 bischof root 0 Apr 18 07:58 fd/ -r--r--r-- 1 bischof root 0 Apr 18 07:58 maps -rw------- 1 bischof root 0 Apr 18 07:58 mem dr-x------ 2 bischof root 0 Apr 18 07:58 mmap/ lrwx------ 1 bischof root 64 Apr 18 07:58 root -> [0305]:2 -r--r--r-- 1 bischof root 0 Apr 18 07:58 stat -r--r--r-- 1 bischof root 0 Apr 18 07:58 statm $ ls -l self/fd total 5 lrwx------ 1 bischof root 64 Apr 18 07:58 0 -> [0305]:24725 lrwx------ 1 bischof root 64 Apr 18 07:58 1 -> [0305]:24725 lrwx------ 1 bischof root 64 Apr 18 07:58 2 -> [0305]:24725 lrwx------ 1 bischof root 64 Apr 18 07:58 3 -> [0305]:2090 lrwx------ 1 bischof root 64 Apr 18 07:58 4 -> [0001]:66846727 $ od -c self/cmdline 0000000 o d \0 - c s e l f / c m d l i 0000020 n e 0000022
Geräte erfüllen fast die Betriebsbedingungen für Dateien. Deshalb kann man spezielle inodes anlegen, die bei Zugriff nicht mit Dateien im Dateisystem sondern mit Geräten arbeiten: Siehe auch sd4
$ ls -l /dev 2975 -rwxr-xr-x 1 root staff 12739 Jan 21 1994 MAKEDEV 2973 crw-rw-rw- 1 root staff 69, 0 Jun 9 1995 audio 2976 crw-rw-rw- 1 root staff 69, 1 Jun 9 1995 audioctl 3428 crw-rw-rw- 1 root staff 26, 0 May 10 1993 bwone0 3433 crw-rw-rw- 1 root staff 39, 0 May 10 1993 cgfour0 2982 crw--w--w- 1 root wheel 0, 0 Apr 7 09:21 console 2993 crw-rw-rw- 1 root staff 22, 0 May 10 1993 fb 3023 crw-rw-rw- 2 root staff 54, 2 Apr 1 15:48 rfd0 2984 crw-r----- 1 root kmem 3, 0 May 10 1993 mem 2991 crw-rw-rw- 1 root staff 13, 0 May 10 1993 mouse 3365 crw-rw-rw- 1 root staff 18, 12 Feb 8 1995 nrst8 2986 crw-rw-rw- 1 root staff 3, 2 Apr 7 10:56 null 3511 crw-rw-rw- 1 root staff 21, 27 May 10 1993 ptyqb 3070 crw-r----- 2 root operator 17, 22 Aug 24 1995 rbackup_4 3070 crw-r----- 2 root operator 17, 22 Aug 24 1995 rsd2g 3442 crw-rw-rw- 1 root staff 30, 8 May 10 1993 rmt8 3049 crw-r----- 1 root operator 17, 9 May 10 1993 rsd1b 2983 crw-rw-rw- 1 root staff 2, 0 Apr 6 11:49 tty 2989 crw-rw-rw- 1 root staff 12, 0 Jul 15 1993 ttya ... $ mknod crt c 10 1 Zeichenorientiertes Gerät eintragen. $ mknod fd b 17 3 blockorientiert
Siehe auch mknod
Abgesehen von speziellen Geräten ist der Zugriff im allgemeinen nicht nützlich oder erlaubt.
In UNIX sind Geräte keine Dateien und können auch nicht mit Dateioperationen in ihrem Verhalten manipuliert werden. Ist dies erforderlich, muß ioctl verwendet werden. Unter Plan 9 ist alles Datei, und alles kann durch Dateimanipulation erreicht werden. Ein kill pid wird zu echo kill > /proc/pid/cntl.
Bei der Ausgabe von ls erkennt man drei wesentliche Angaben pro Geräte-Inode: b und c unterscheidet block- und zeichenorientierte Geräte, und in jeder der beiden Gruppen gibt es einen ersten Index (major), der die Geräteklasse (Terminal, Platte, ...) wählt, sowie einen zweiten Index (minor), der in der Klasse zum Beispiel ein bestimmtes Gerät oder eine Betriebsart definiert.
Block- und Zeichen-Orientierung ergibt sich daraus, daß der Zugriff im Betriebssystem über zwei Tabellen erfolgt, die primär Funktionen enthalten:
bdevsw[] .open .close .strategy cdevsw[] .open .close .read .write .ioctl
b oder c wählen die Tabelle, major die Zeile in der Tabelle, minor wird als Argument an die Treiberfunktion übergeben. Die Funktionen .open und .close können zum Beispiel exklusiven Zugriff auf ein Gerät erzwingen oder kontrollieren, ob eine Floppy eingelegt ist.
Bei Block-Geräten werden Puffer fixer Größe an .strategy übergeben. Diese Funktion sorgt dann für den Transfer zum Gerät in einer möglichst effizienten Reihenfolge. Siehe auch mknod(8) und mknod(2)
Bei Zeichengeräten transferieren .read und .write sequentiell ziemlich beliebig viele Zeichen. ioctl implementiert Gerätesteuerungen wie stty oder Formatierung einer Floppy.
Am Anfang kennt das Betriebssystem nur ein Dateisystem (die root).
inode-Nummern sind (als Vektorindizes) in einem Dateisystem eindeutig. Sie verweisen nicht auf andere Dateisysteme.
Man kann dem Betriebssystem mittels mount mitteilen, daß eine inode temporär im eigenen Betriebssystem als Wurzel eines anderen Dateisystems verstanden werden soll:
$ mount /dev/fd /mnt Dateisystem auf Gerät mit Hierarchie verbinden. $ mount Tabelle zeigen $ umount /dev/fd Dateisystem wieder entfernen
Durch mount könnte das früher gezeigte Dateisystem zum Beispiel so erweitert werden:
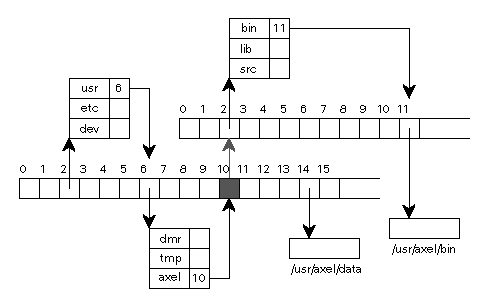
Whärend des boot-Vorgangs werde in aller Regel die in /etc/fstab festgelegten Dateisystem montiert.
Entfernte Dateisystem werden, falls möglich, mittels automount montiert.
$ cd /var/yp/src
$ ls aut*
auto.direct auto.direct.was auto.master
auto.direct.old auto.home auto.vol
$ cat auto.home | sed 5q
# auto.home
# mounted at /home, everybody's home directory
bischof portos:/export/home/bischof
hp -rw,anon=0 thor:/export/home/hp
$ cat /etc/rc.local
....
#
# start up the automounter
#
LOCALSERVER1=thor; export LOCALSERVER1
LOCALSERVER2=thor; export LOCALSERVER2
if [ -f /usr/etc/automount ]; then
automount && echo -n ' automount '
# automount -tl ${AUTOTIME:=300} && echo -n ' automount'
fi
echo '.'
...
$ cat auto.direct
# auto.direct
# can be hierarchical, mounted almost always
#
# LOCALSERVER1, ... serve /usr/local for architecture
# ARCH architecture-specific
/usr/distrib -ro thor:/export/home/distrib
/usr/local \
/ -rw $LOCALSERVER1:/export/local/$ARCH/local \
$LOCALSERVER2:/export/local/$ARCH/local \
/X -rw iduna:/export/X11R6
/usr/man -rw thor:/export/man/$ARCH
/usr/openwin -rw thor:/export/openwin
Es gibt viele Varianten. Wenn zum Beispiel die root nur für Lesezugriff montiert wird, werden eine Reihe der hier beschriebenen Dateien und Kataloge mit symbolischen Links in einen Bereich verlegt, für den es Schreibzugriff gibt (/var oder /private). Wenn ein System in einem Netz verwaltet wird, existiert manche Information nicht in Dateien sondern als Tabelle in einer Datenbank (NIS oder NetInfo).
/ Wurzel bin/ wichtigere Kommandos (sh) boot Hilfsprogramm zum Systemstart dev/ Geräte console Systemkonsole fd0 Diskettenlaufwerk lp Zeilendrucker mem Speicher insgesamt null ewige Jagdgründe tty aktuelles Terminal tty1a Terminal an serieller Schnittstelle ttyp1 Terminal an Netzverbindung (Pseudo-Terminal) etc/ Systemverwaltung group Gruppen: Name/Nummer init Programm für ersten Prozeß mount Dateisystem verknüpfen passwd Benutzer: Name/Nummer umount Dateisystem abmelden home/ Heimatkataloge der Benutzer username/ ...der Benutzer username bin/ ganz private Kommandos lib/ Bibliotheken, Hilfsdateien libc.a C Bibliothek lost+found/ zur Reparatur des Dateisystems tmp/ temporäre Dateien unix System (für boot, ps) usr/ Benutzer adm/ Systemverwaltung: Verbrauch bin/ restliche Kommandos include/ Definitionsdateien für C lib/ Bibliotheken, Textmakros, ... local/ lokale Entwicklungen bin/ lokale Kommandos lib/ lokale Bibliotheken man/ online Manual spool/ Bereich für Kommunikationsprogramme lp/ Druckaufträge mail/ elektronische Post tmp/ temporäre Dateien (sort) tmp/ temporäre Dateien
Dateisysteme können inkonsistent werden. Mit fsck(8) kann ein Reperaturversuch unternommen werden. Dies ist im Ernstfall nicht trivial und nicht dem Moment um zu üben. Mit minx kann man gefahrlos üben.
minx [Schreiner System-Programmierung in UNIX Band 2, Teubner 1986] ist ein Beispiel für einen UNIX-artigen Dateimanager in Form eines Programms, das unter UNIX und sogar DOS läuft. In dem System kann mit Zugriff auf Dateien und Pflege von Dateisystemen auch ohne Super-User-Privilegien experimentiert werden.
Startet man minx so kann man kurze Beschreibungen der möglichen Kommandos anfordern:
$ minx ... 1 $ cat /man/1 zeigt die allgemeinen Kommandos 1 $ cat /man/4 zeigt die Geräte 1 $ cat /man/8 zeigt Kommandos zur Pflege
minx wurde auch dazu konstruiert, das Innenleben einer Implementierung des Dateisystems zu zeigen. Details findet man in der o.a. Literatur.
Beispiele
$ minx=/home/sp/Skript/Code/Minx/NeXT/minx Kommando erreichen
$ $minx aufrufen
minx v1.11
Copyright (c) 1985,
1994 Axel T.
Schreiner,
Osnabrueck,
Germany
1 $ ls ls ausprobieren
.:
./dev
./man
1 $ ls -l /dev/A: NeXT Floppy-Laufwerk
br-------- 1 0/0 1,
0 /dev/A:
1 $ rm -r man abräumen
1 $ mknod platte b 1 0 Gerät anlegen
1 $ mkfs platte 20 wenn Panel erscheint,
Floppy einlegen,
damit Dateisystem angelegt werden kann
platte: device 1/0
isize 1 (16 files),
fsize 17 (20 blocks total)
1 $ mount platte dev einbinden
1 $ echo hallo >dev/file Datei erzeugen
1 $ cat /dev/file und anschauen
hallo
1 $ umount platte abmelden
1 $ icheck /dev/A: inodes prüfen
/dev/A:: device 1/0
isize 1 (16 files),
fsize 17 (20 blocks total)
15 free blocks
2 used blocks
3 used inodes
1 file
1 directory
1 $ dcheck platte links prüfen
platte: device 1/0
isize 1 (16 files),
fsize 17 (20 blocks total)
1 $ ^D beenden
$ /usr/etc/disk -e /dev/rfd0b wieder in UNIX: Floppy entfernen
disk name: Sony MPX-111N 2880
disk type: removable_rw_floppy
Das erste Dateisystem ist Teil des Simulators minx selbst, das heißt, es steht im Hauptspeicher und kann beliebig zerstört werden. Beim nächsten Aufruf von minx ist es neu vorhanden.
Dateisysteme auf Disketten sind natürlich nicht kompatibel mit NeXTSTEP.
Kommandos
NAME DESCRIPTION SYNOPSIS cat catenate and print cat [arg...] cd change working directory cd [dir] chgrp change group chgrp id file... chmod change mode chmod mode file... chown change owner chown id file... cp copy cp old new cp old... dir echo echo arguments echo [-n] [arg...] exit logout exit ln make a link to a file ln old [new] ln old... dir ls list contents of directory ls [-adilR] [arg...] mkdir make a directory mkdir dir... mv move or rename a file mv old new mv old... dir mount mount file system mount special name pwd print working directory name pwd rm remove files rm [-r] arg... rmdir remove directories rmdir dir... set set trace flags set [-+!~] [-0..z] [buf inode file io name svc] sh (fake) shell sh [-+!~] [-0..z] [buf inode file io name svc] sync update super block sync umount dismount file system umount special ^D logout ^D or end of file clri clear inode clri fs inum... dcheck check directory consistency dcheck [-i inum...] [fs] icheck check storage consistency icheck [-s] [-b bnum...] [fs] ipatch modify inode ipatch fs login set user id login [-e] id mkfs construct file system mkfs fs blocks mknod build special file mknod name b|c major minor newgrp set group id newgrp [-e] id who show identification who
In der typischen Konfiguration am NeXT wird minx mit einem speicher-residenten Dateisystem gestartet, das folgende Gerätedateien enthält:
memory /dev/root block 0/? root filesystem disk /dev/A: block 1/0 internal floppy drive /dev/B: block 1/1 [illegal] null device /dev/null character 0/? read: end of file write: black hole terminal /dev/tty character 1/? read: stdin /dev/tty character 1/!=2 write: stdout /dev/err character 1/2 write: stderr
Eine Floppy darf unbedingt erst dann eingelegt werden, wenn ein entsprechendes Panel erscheint. Nach Ende von minx entfernt man die Floppy mit dem Kommando
$ /usr/etc/disk -e /dev/rfd0b
minx enthält eine Vielzahl von Ablaufverfolgungen, die mit set bei + gesetzt, bei ! gelöscht und bei ~ komplementiert werden. Sie können einzeln oder in Gruppen angegeben werden, wobei - für alle steht:
0 fpy.c floppy disk block driver 1 mem.c memory block driver 2 null.c null character driver, c.c stubs 3 std.c stdio terminal character driver 4 name.c additionally show name scan 5 trace.c show Uerror if not null 6 tfil_ additionally show inode and data buffer 7 fshow_ show open files 8 ishow_ show inode cache contents 9 bshow_ show buffer cache contents A balloc_ calloc next free block to cache buf B bcache_ block to cache C bclose_ end using device D bdone_ release block in cache E bfree_ add block to free list F blockio perform i/o for buffer G bopen_ begin using device H bwrite_ mark block to be written I ialloc_ get free inode, set link count to 1 inode J icache_ inode to cache K idone_ release inode in cache L inodeio perform i/o for inode M imount_ mount dev onto dp N itrunc_ cut inode to size zero O iumount_ dismount dev P iunlink_ reduce link count Q iwrite_ mark inode to be written R fclose_ release file file S fcreat_ file from next free inode T fd_ unused file descriptor U fopen_ file from existing inode V fp_ convert file descriptor to open file W ftrunc_ cut file to size zero X ifread_ read file io Y ifseek_ position file Z ifwrite_ write file a nchdir_ dirty work for chdir/chroot name b nlink_ write i,component[] into fp c nopen_ file pointer for existing name d nprot_ check protection e access check access permission svc f chdir change directory g chmod change mode of a file h chown change owner and group of file i chroot change root directory j close close file access k creat create or truncate file l dup duplicate file descriptor m dup2 ... to particular file descriptor n exit terminate process o fstat get information about file descriptor p link make additional link to file q lseek position r mknod create inode s mount mount file system t open open file access u read read from file descriptor v stat get information about file w sync write all cached blocks x umount unmount file system y unlink remove link to file z write write to file descriptor
Der Begriff kommt aus der Automatentheorie: reguläre Sprachen kann man mit endlichen Automaten, also ohne Rekursion, analysieren. Nicht analysieren kann man zum Beispiel ein beliebig tiefes Klammergebirge.
Reguläre Ausdrücke sind Suchmuster, die reguläre Sprachen beschreiben und sehr effizient implementiert werden können.
Die Theorie findet man in Compilerbau von Aho, Sethi und Uhlmann, oder in Compiler Design in C von Holub.
Eine mögliche Implementierung samt Simulation ist re.c, gute public-domain-Quellen stammen von GNU.
Für praktischen Gebrauch gibt es reguläre Ausdrücke in Kommandos:
Zur Generierung von Dateinamen und bei Kontrollstruktur case. gibt es in der Shell folgende Operationen :
c normalerweise stellt ein Zeichen sich selbst dar \c 'c...' "c..." Sonderbedeutung unterdrücken ? beliebiges, einzelnes Zeichen * beliebig viele beliebige Zeichen [...] einzelnes Zeichen aus Klasse, auch Bereich a-z [!...] einzelnes Zeichen nicht aus Klasse (nicht X/Open) r1r2 r1 und dann r2 r1|r2 case r1 oder r2
Bei Dateinamen werden . am Anfang und / überall nur explizit erkannt.
Beispiele:
$ ls ? * $ ls -l * -rw-r--r-- 1 bischof inform 0 Apr 10 10:03 * -rw-r--r-- 1 bischof inform 0 Apr 10 10:03 c.01 -rw-r--r-- 1 bischof inform 0 Apr 10 10:03 c.02 -rw-r--r-- 1 bischof inform 0 Apr 10 10:03 c.09 -rw-r--r-- 1 bischof inform 0 Apr 10 10:03 ccb -rw-r--r-- 1 bischof inform 0 Apr 10 10:03 ccr -rw-r--r-- 1 bischof inform 0 Apr 10 10:03 fiver $ ls '*' * $ ls -l c*[0-9] -rw-r--r-- 1 bischof inform 0 Apr 10 10:03 c.01 -rw-r--r-- 1 bischof inform 0 Apr 10 10:03 c.02 -rw-r--r-- 1 bischof inform 0 Apr 10 10:03 c.09 $ ls -l 'c*[0-9]' ls: c*[0-9]: No such file or directory $ ls c.0[!29] c.01 $ ls ??[!b] ccr
Bei regulären Ausdrücken gibt es mit abnehmendem Vorrang folgende Operationen :
c normalerweise stellt ein Zeichen sich selbst dar
\c Sonderbedeutung unterdrücken
^ Zeilenanfang
$ Zeilenende
. beliebiges, einzelnes Zeichen
[...] einzelnes Zeichen aus Klasse, auch Bereich a-z
[^...] einzelnes Zeichen nicht aus Klasse
\(r\) grep markierter Ausdruck
\n grep was die n-te \(r\) erkannte
r* beliebig viele r
r+ egrep ein oder mehr r
r? egrep ein oder kein r
r\{m,n\} Anzahl, r von m bis n mal
r\{m,\} Anzahl, r mindestens m mal
r\{m\} Anzahl, r genau m mal
r1r2 r1 und dann r2
r1|r2 egrep r1 oder r2
(r) egrep Klammerung für Vorrang
Vorsicht: mit Ausnahme von \n bei lex erkennt kein regulärer Ausdruck einen Zeilentrenner.
Beispiele Hier sind zum Vergleich die gleichen Beispiele als grep-Muster:
\.c$ C-Quellen ^cmd\..$ Dateien für cmd ^[A-Z] Dateinamen mit großen Anfangsbuchstaben ^[^A-Z] andere Dateinamen ^c\.[1-9]?[0-9]$ ein großes Buch (plus ein Kapitel) [^./] Dateinamen mit einem Zeichen, nicht . oder / ^\. alle Dateinamen, die mit . anfangen ^\.[^.] alle mit . aber nicht . und .. ^\.(..|[^.]) besser (egrep)
Vorsicht: Reguläre Ausdrücke erkennen die längste Zeichenkette, und sie sind nur verankert, wenn ^ und $ benutzt werden. Manche egreps haben (8-Bit-)Fehler.
Wortspiele
/usr/dict/words (siehe auch spell ) enthält (oft) ein englisches Wörterbuch. Bei NeXT gibt es zusätzlich die Wort- und Stammliste /usr/dict/web2. Kernighan und Pike schlagen folgende Muster für Wortspiele vor:
$ egrep '^a?b?c?d?e?f?g?h?i?j?k?l?m?n?o?p?q?r?s?t?u?v?w?x?y?z?$' \ /usr/dict/words | sed 3q a abc abet
monotone liefert Worte mit Buchstaben in natürlicher Reihenfolge:
$egrep '^[^aeiou]*a[^aeiou]*e[^aeiou]*i[^aeiou]*o[^aeiou]*u[^aeiou]*$'\ /usr/dict/words | sed 3q facetious
liefert Worte mit exakt fünf aufsteigenden Vokalen:
Vorsicht: grep kennt die Option -f nicht.
Nützliche grep-Optionen:
-e re egrep Präfix für reguläre Ausdrücke -f file nicht grep Ausdruck aus Datei -l Dateiname ausgeben, falls Zeile gefunden -n Zeilennummer ausgeben -v (veto) nur wenn Muster nicht zutrifft -x fgrep ganze Zeile muß passen -y groß und klein gleich (X/Open: -i)
Editoren wie vi, oder sed benützen einfache reguläre Ausdrücke, das heißt, sie erlauben Markierungen. Textersatz kann auf die Markierung Bezug nehmen:
$ echo 'a b' | sed 's/\(.*\) \(.*\)/\2 \1/' b a
Damit kann man Spalten tauschen oder verdoppeln.
sed bearbeitet seine Standard-Eingabe und kann zur Text-Extraktion benützt werden:
$ date | sed 's/.*\(..:..:..\).*/It is now \1/' It is now 17:31:42
expr kann Muster mit : erkennen; dabei produziert eine Markierung den Text als Standard-Ausgabe:
$ expr "`date`" : '.*\(..:..:..\)' 8:32:21
expr ist ein kleineres Programm als sed aber manchmal verwirrend:
$ echo It is now `expr "\`date\`" : '.*\(..:..:..\)'` It is now 17:35:05
Man beachte, daß auch set set (in der Shell eingebaut) extrahieren kann:
$ set `date` $ echo $1 "---" $2 Thu --- Apr $ date Thu Apr 10 12:04:15 MET DST 1997 $ $ set `date` $ echo It is now $4 It is now 17:36:48
$ find / -name wildcard -print $ du -a / | cut -f 2 | egrep pattern
wildcard bezieht sich auf jede Pfad-Komponente. pattern ist ein erweiterter regulärer Ausdruck, der sich auf den ganzen Pfad bezieht.
$ vi `find / -name test.c -print`
test.c editieren, egal wo es sich befindet. Es gibt Probleme, wenn ein Katalog test.c heißt.
Dieses Problem kann durch
$ vi `find / -type f -name test.c -print`
umgangen werden.
$ vi `fgrep -l variable *.[ch]`
Jede C-Quelle und Definitionsdatei editieren, die einen bestimmten Variablennamen enthält. Nicht empfohlen für Variblennamen wie i.
$ tr ' \12' '\12 ' | tr -d ' ' | grep -- -
Wörter mit Bindestrich zeigen, auch wenn sie über Zeilen getrennt sind.
$ grep '\([^ ]\{2,\}\) \1'
Doppelte Wörter zeigen. Zeigt aber auch gleiche Nach- und Vorsilben.
$ tr ' \12' '\12 ' | grep '\([^ ]\{2,\}\) \1'
Nach- und Vorsilbe am Ende und Anfang aufeinanderfolgender Zeilen. Hat Probleme bei Zeilen mit einzelnen Worten und bei der letzten Zeile.
#!/bin/sh
{ tr ' \12' '\12 '; echo; } |
sed '/\([^ ]\{2,\}\) \1/!s/[^ ]//g' |
tr ' \12' '\12 ' |
grep -n '[^ ]'
Analog, Ausgabe zeigt aber Position.
#!/bin/sh
while read x
do
eval "case \$x
in *$1*) echo \$x
esac"
done
grep mit Shell-Mustern. echo beschädigt aber die Ausgabe...
Ein Kommando besteht aus einer Folge von Worten.
Zuweisungen am Beginn eines Kommandos gelten nur für die Ausführung des Kommandos allerdings mit leichten Unregelmäßigkeiten:
$ x=x $ x=5 3>z date normales Kommando Thu Apr 10 13:39:25 MET DST 1997 $ echo $x x $ x=4 >z echo hi eingebautes Kommando $ echo $x 4 $ x=3 >z leeres Kommando, normale Zuweisung $ echo $x 3
Umlenkungen können überall im Kommando stehen. Zuweisungen werden nach dem Kommandonamen nur als solche erkannt, wenn die Option -k gesetzt ist. Allerdings werden Variablen ersetzt bevor die Zuweisungen ausgeführt werden, Zuweisungen werden von rechts nach links ausgeführt und die Zuweisungen gelten bei nicht-eingebauten Kommandos nur für das Kommando:
$ set -k $ x=9; x=10 \ ed \ x=11 y=12 $x; echo $x 9? ! echo $x 10 ^D 9 $ x=9; x=10 echo x=11 $x; echo $x eingebautes Kommando 9 10 $ a=9; echo $a; a=8 b=$a a=10 b=$a$a; echo $a $b 9 8 10
Das erste Wort im Kommando, das weder eine Zuweisung noch eine Umlenkung ist, legt fest, welches Kommando ausgeführt wird:
$ test # eingebaut oder Funktion $ date # über PATH gesucht $ /bin/echo # absoluter Pfad $ ./test # relativ, hier im aktuellen Katalog
Enthält das erste Wort keinen / so wird unter den eingebauten Kommandos, dann den Funktionen und dann in jedem Katalog gesucht, der in PATH angegeben ist. Die Variable wird normalerweise bei der Anmeldung ausreichend definiert.
$ echo $PATH ::/home/bischof/bin/i386:/home/bischof/bin:/usr/bin/X11:...
PATH sollte den aktuellen Katalog als . oder als leeren Eintrag enthalten üblicherweise zuerst. Beim Super-User enthält PATH den aktuellen Katalog a priori aus Sicherheitsgründen nicht.
type zeigt, wo ein Kommando im Dateisystem zuerst gefunden wird. Das Kommando ist in der Shell eingebaut:
$ type awk echo awk is /bin/awk echo is a shell builtin
which zeigt, wo ein Kommando im Dateisystem zuerst gefunden wird, falls die csh verwendet wird.
whereis zeigt, Information zu einem Wort gefunden werden kann.
$ whereis man ls man: /usr/ucb/man /usr/local/man /usr/man/man1/man.1 /usr/man/man7/man.7 ls: /bin/ls /usr/man/man1/ls.1
Das eigentliche Problem besteht darin, daß Textersatz stattfindet.
Ein Kommando in `...` wird durch seine Standard-Ausgabe ersetzt. Zeilentrenner am Schluß werden entfernt:
$ echo `hostname` hat `who | wc -l` Benutzer next hat 2 Benutzer $ echo linux hat "`rsh linux who | wc -l`" Benutzer linux hat 1 Benutzer
Kommandos werden auch innerhalb von "..." ersetzt, wobei dann nur ein Argument als Resultat entsteht. Sonst wird die Ausgabe an den Zeichen in Worte zerlegt, die in IFS stehen, wobei zusätzlich gilt
$ IFS=: $ echo `ypcat passwd | grep bischof | grep H` bischof 9Y.UyH7/PzuOY 106 11 Hans-Peter Bischof /home/bischof /usr/local/gnu/bin/bash
Allgemein schützen '...' und "..." vor Nachzerlegung an IFS.
$ echo "`ypcat passwd | grep bischof | grep H`" bischof:9Y.UyH7/PzuOY:106:11:Hans-Peter Bischof:/home/bischof:/usr/local/gnu/bin/bash
Ungeschützte Argumente, Variablenwerte und Kommando-Ausgabe werden nachzerlegt, Dateinamen aber nicht:
$ IFS=: $ echo hello > a:b; ls a:b $ x='c:d'; echo * $x e:f "$x" `echo '1:2'` "`echo '3:4'`" a:b c d e f c:d 1 2 3:4
Innerhalb von `...` wird \ zweimal bearbeitet:
$ a='echo `date`' $ $a `date` $ echo $a $ `echo $a` $ `echo \$a` $ `echo \\$a` $ `echo \\\$a` $ `echo \\\\$a` $ a='eval echo `$a`' $ $a
Das letzte Beispiel ist eine endlose Schleife...
Man kann `...` schachteln, wenn man die innere Gruppe mit \ schützt:
$ echo Tag: `set `date`; echo $2` Tag: 21
Die Werte von Shell-Variablen werden durch $name abgerufen. Die Werte stammen aus Zuweisungen. Eine Folge von Zuweisungen wird von rechts bearbeitet. Wenn nicht durch "..." geschützt wird, wird der Wert dann noch an IFS zerlegt. Der Wert wird nur einmal ersetzt:
$ set -x; IFS=:; a=$b b='c:d e' IFS=: b=c:d e a=c:d e $ echo $a "$b" + echo c d e c:d e c d e c:d e $ a='$b'; echo $a $b
Die Shell setzt einige spezielle Variablen:
$1 ... $9 Argumente $# Anzahl der Argumente $* und $@ alle Argumente "$*" alle Argumente als ein Wort "$@" alle Argumente als einzelne Wörter $- Optionen der aktuellen Shell $? Exit-Code des letzten Kommandos $! Prozeßnummer des letzten Hintergrund-Kommandos $$ Prozeßnummer der Shell (falsch bei Sub-Shell)
Das System verwendet einige Variablen; eine Auswahl:
HOME login Heimatkatalog (für cd) IFS space tab newline trennende Zeichen für Worte MAIL leer (versucht, Post zu überwachen) PATH :/bin:/usr/bin Suchpfade für Kommandos PS1 '$ ' Prompt PS2 '> ' Prompt bei Fortsetzung SHELL /bin/sh Name der Shell TERM login Terminaltyp TZ MEZ-1MESZ,M4.5,M9.5 Interpretation des Datums
Mit Doppelanführungszeichen kann man Variablen einigermaßen als Wertelisten verwenden:
$ tee a.c b.c c.c </dev/null $ o= $ for i in *.c; do o="$o `basename $i .c`.o"; done $ echo $o a.o b.o c.o
Dabei muß man allerdings sehr vorsichtig mit Zwischenraum umgehen:
$ ls a a b b $ # Doppelpunkt und Zeilentrenner $ IFS=': > ' $ f=; for i in `ls`; do f="$f:$i"; done $ set $f $ echo $2 a b
Argumente sind $1 bis $9. Der Name des Shell-Skripts selbst ist $0; er kann Pfadanteile enthalten. Das folgende Skript gibt seine Eingabe n-spaltig aus, wobei n der Name des Skripts ist:
#!/bin/sh pr -t -l1 -`basename $0`
Argumente stammen aus der Kommandozeile, das heißt, der Systemaufruf execv(const char * pfad, const char * argv []); ersetzt den Programmtext des aufrufenden Prozesses durch das Programm in der Datei pfad und übergibt den Vektor argv[] samt seinen Zeichenketten an das neue Hauptprogramm. Der Speicherbedarf des Vektors und der Zeichenketten, also die Länge der expandierten Kommandozeile, ist begrenzt kann aber relativ groß sein.
Alle Argumente (auch mehr als 9) sind durch $* oder $@ erreichbar. "$*" liefert sie als ein Wort, verkettet mit Leerzeichen. "$@" liefert sie als ein Argument pro Wort:
1 #!/bin/sh 2 3 for i in $* 4 do 5 echo '$*:' $i 6 done 7 echo "----------------" 8 9 for i in "$*" 10 do 11 echo '"$*":' $i 12 done 13 echo "----------------" 14 15 for i in $@ 16 do 17 echo '$@:' $i 18 done 19 echo "----------------" 20 21 for i in "$@" 22 do 23 echo '"$@":' $i 24 done 25 26 exit 0
$ 6.args a b $*: a $*: b ---------------- "$*": a b ---------------- $@: a $@: b ---------------- "$@": a "$@": b $ 6.args "A B" $*: A $*: B ---------------- "$*": A B ---------------- $@: A $@: B ---------------- "$@": A B
Argumente können auch mit set gesetzt werden:
$ set `date`; echo $4 17:14:29
shift verschiebt alle Argumente nach links, eventuell um mehrere Positionen:
$ shift `expr $# - 1`; echo $1 1997
Eine Funktion verwendet die gleichen Argumente wie die Shell selbst, das heißt, ein Funktionsaufruf hat praktisch set als Nebeneffekt:
$ f()
> { shift $1; }
$ f 3 a b c d e; echo $*
c d e
Alle Argumente (auch mehr als 9) sind durch $* oder $@ erreichbar. "$*" liefert sie als ein Wort, verkettet mit Leerzeichen. "$@" liefert sie als ein Argument pro Wort:
$ echo heute > a; echo morgen > b; echo jetzt > 'a b'; ls a a b b $ cat * heute jetzt morgen $ set *; cat "$@" heute jetzt morgen $ cat $* heute heute morgen morgen $ cat "$*" cat: a a b b: No such file or directory
Vorsicht: leere Anführungszeichen erzeugen leere Argumente; nicht alle Kommandos reagieren vernünftig auf leere Argumente:
$ e() { ed "$@"; }
$ e a
6
q
$ e # leert Argumentliste
?
q
$ ls "$@"
a a b b
$ rm -i "$@" leeres Argument
rm: : is a directory
$ rm -i ${1:+"$@"} kein Argument
Try `rm --help' for more information.
Zum Abruf von Variablenwerten gibt es folgende zusätzliche Syntax:
${name} {...} begrenzen name gegen nachfolgenden Text
${name?message} Wert oder Fehlermeldung mit message (auch leer)
${name=default} Wert oder default; letztere wird dann Wert
${name-default} Wert oder default; Wert bleibt aber leer
${name+ersatz} ersatz, falls es Wert gibt; sonst nichts
Der Test bezieht sich mit Doppelpunkt darauf,
ob name existiert und keinen leeren Wert besitzt.
Ohne Doppelpunkt wird nur Existenz geprüft.
Eine Zuweisung an Argumente, also etwa ${1=default}, ist nicht möglich. Die anderen Formen sind auch für Argumente erlaubt. Der Ersatz muß jeweils ein einziges Wort sein.
Nach Ersatz von Variablen und Kommandos werden aus den nicht zitierten Wörtern, also auch aus dem Ersatztext von Variablen, Dateinamen generiert. Aus einem Wort entsteht jeweils eine alphabetisch sortierte Namensliste die Listen werden nicht zusammengefügt. Das Resultat der Generierung wird weder nachersetzt noch an IFS zerlegt.
$ echo hi > a=b $ a=* $ echo "$a" * $ echo $a a=b
Allgemein folgt, daß man Variablen und Kommandos wohl grundsätzlich mit "..." schützen sollte:
$ read x; echo $x * a=b
Da Muster in Variablen aufbewahrt werden, muß man Dateilisten sorgfältig konstruieren:
$ tee a b c </dev/null $ files=*; echo "$files" $files * a a=b b c $ files=`echo *`; echo "$files" a a=b b c $ `echo ???` a=b: execute permission denied $ eval `echo ???`; echo $a b
Zuweisungen am Anfang (nach set -k überall) und Umlenkungen werden ausgelassen; das erste übrige Wort ist das Kommando, der Rest sind Argumente. Die Umlenkungen werden angewendet, die Zuweisungen werden normalerweise lokal zum Kommando exportiert.
$ test -f file && rm file & # insgesamt im Hintergrund
Ein Kommando ist entweder eine Liste, also auch eine Pipeline oder ein einfaches Kommando, oder es ist eine Kontrollstruktur:
for variable # durchläuft $1 ...
do liste
done
for variable in wort...
do liste
done
while liste # Exit-Code Null?
do liste
done
until liste # Exit-Code nicht Null?
do liste
done
if liste # Exit-Code Null?
then liste
elif liste # viele elif ...können entfallen
then liste
else liste # ein else ...kann entfallen
fi
case wort
in muster | muster ) # wie Dateimuster,
erkennen auch /
liste
;; muster ) # viele Fälle
liste
esac
{ liste ;} # Zusammenfassung,
gleiche Shell
( liste ) # Sub-Shell (also fork)
name() { liste ;} # definiert Funktion
Der Exit-Code stammt vom letzten Kommando if, while und until liefern Null, wenn kein Kommando ausgeführt wird.
E/A-Umlenkung ist für die ganze Kontrollstruktur möglich, denn sie gilt wieder als Kommando. Das führt dann aber zu Sub-Shells.
Vorsicht: Die ganzen steuernden Worte sind nicht reserviert insbesondere sind nur die runden Klammern reserviert, die geschweiften nicht!
Eine Reihe von Kommandos sind in der Shell eingebaut, Kommandos wie cd oder set -k wirken auf Informationen in der Shell selbst, bei anderen wie echo oder test geschieht das aus Effizienzgründen. Nach XPG3 sind eingebaut:
$ eval 'date; who' Thu Apr 10 15:12:43 MET DST 1997 bischof ttyp1 Apr 10 09:00 (:0.0)
$ exec >&2 2>/dev/null
Fast alle Optionen können mit set eingeschaltet (-x) und ausgeschaltet (+x) werden. Alle Optionen können als Kommandoargumente beim Aufruf von sh verwendet werden. Nach XPG3 gibt es folgende Optionen:
zum Beispiel bei set
-a, -k und -u realisieren einen anderen Stil zum Umgang mit Variablen. -n, -v und -x dienen vor allem zur Fehlersuche. Mit -c und -i zusammen mit -t kann man Shell-Service in anderen Applikationen realisieren.
-e hat etwas verblüffende Eigenschaften:
$ set -e; false; echo $? 1 $ test; echo $? 1 $ false
Offenbar wirkt -e erst auf die nächste Zeile und nicht auf Fehler in eingebauten Kommandos.
Ein Skript soll als optionales Argument ein Zahl (NF) bekommen, und danach Text-Zeilen einlesen, und von der Zeile das NF. Feld ausgeben. Der Aufruf-syntax könnte wie folgt aussehen:
nf [i]
Man kann davon ausgehen, daß i eine Zahl ist. Das Problem soll ohne cut gelöst werden.
Siehe 6.nf_[12]
Erkären Sie folgenden Sachverhalt:
artemis Src 61 6.nf_2 1 Ein Ein -x + eval echo $1 + echo Ein Ein + read LINE
Siehe 6.nf_3
Die Argumentbehandlung geht noch etwas kürzer. Siehe 6.nf_4
Viele Probleme haben eine relativ einfache erste Lösung. Von dort bis zu einem robusten Skript für den täglichen Gebrauch kann es aber ein weiter Weg sein. Deshalb erscheinen hier in der Regel mehrere Lösungen zum gleichen Problem. Dieses Kapitel beschäftigt sich mit relativ kleinen Skripten.
Shell-Virus
McIlroy gab folgendes Rezept für einen Shell-Virus an [unix/mail 1/1990]:
1 #!/bin/sh 2 3 for i in "$@" #virus# 4 do case "`sed 1q $i`" 5 in "#!/bin/sh") grep '#virus#' $i > /dev/null || 6 sed -n '/#virus#/,$p' $0 >> $i 7 esac 8 done 2> /dev/null 9 10 exit 0
Dies hat folgende Konsequenz:
$ cat v1
#!/bin/sh
echo '#virus#'
exit 0
$ 7.virus v1
$ cat v1
#!/bin/sh
echo '#virus#'
exit 0
$ cat v2
#!/bin/sh
$ 7.virus v2
$ cat v2
for i in "$@" #virus#
do case "`sed 1q $i`"
in "#!/bin/sh") grep '#virus#' $i > /dev/null ||
sed -n '/#virus#/,$p' $0 >> $i
esac
done 2> /dev/null
exit 0
Für den Fall, daß ein System ernsthaft kaputtgeht, sollte man sich zum Beispiel ein minimales System auf Diskette zurechtlegen. UNIX-Kerne sind heute jedoch so groß, daß man nur noch sehr wenige Programme in einem solchen Mini-System zur Verfügung stellen kann. Die folgenden Funktionen emulieren deshalb verschiedene nützliche Programme nur mit Hilfe der Shell und dd Da man sie im Ernstfall eintippen muß, sind sie möglichst kurz und nicht unbedingt robust.
1 cat() { # [file ...] simuliert cat mit dd
2 if [ $# = 0 ]
3 then dd 2>&-
4 else for i
5 do dd 2>&- < $i
6 done
7 fi
8 }
9
1 cut() { # [field-number] extrahiert ein [erstes] Feld
2 nf=${1:-1}
3 while read line
4 do set -- $line
5 eval echo \$$nf
6 done
7 }
8
Five -- fünf Argumente pro Zeile
1 five() { # arg... fuenf Argumente pro Zeile
2 until [ $# -lt 5 ]
3 do echo "$1 $2 $3 $4 $5"
4 shift; shift; shift; shift; shift
5 done
6 [ $# -gt 0 ] && echo "$*"
7 }
1 lsR() { # [path...] rekursiv, eingerueckt
2 [ $# = 0 ] && set -- *
3 for i
4 do if [ -f "$i" ]
5 then echo "$indent$i"
6 elif [ -d "$i" ]
7 then ( echo "$indent$i"/
8 cd "$i"
9 indent="$indent "; lsR
10 ) fi
11 done
12 }
1 lsL() { # [path...] viel Information
2 [ $# = 0 ] && set -- *
3 for i
4 do if [ -f $i ]; then t=-
5 elif [ -d $i ]; then t=d
6 elif [ -c $i ]; then t=c
7 elif [ -b $i ]; then t=b
8 elif [ -p $i ]; then t=p
9 fi
10 r=-; [ -r $i ] && r=r
11 w=-; [ -w $i ] && w=w
12 if [ -x $i ]
13 then x=x; [ -u $i ] && x=s
14 else x=-; [ -u $i ] && x=S
15 fi
16 echo $t$r$w$x $i
17 done
18 }
1 lsP() { # [path...] rekursiv, volle Pfade
2 [ $# = 0 ] && set -- *
3 for i
4 do if [ -f "$i" ]
5 then echo "$indent$i"
6 elif [ -d "$i" ]
7 then ( cd "$i"
8 indent="$indent$i/"; lsP
9 echo "$indent"
10 ) fi
11 done
12 }
Gruppen von fuenf Zeilen ausgeben
1 pg() { # Gruppen von fuenf Zeilen ausgeben
2 ( pglen=xxxxx IFS=
3 while read line
4 do echo "$line"; count=x
5 until [ $count = $pglen ]
6 do read line || break 2
7 echo "$line"; count=x$count
8 done
9 read line </dev/tty
10 done
11 )
12 }
Typischerweise sind die Quellen der Manualseiten öffentlich und müssen mit nroff formatiert werden. Diese Version von man geht davon aus, daß die Seiten bereits formatiert sind:
1 #!/bin/sh 2 PATH=/usr/ucb:/bin:/usr/bin 3 4 section=? exit=0 5 6 files= 7 while [ $# -gt 0 ] 8 do case $1 9 in [1-8]) section=$1 10 ;; *) found= 11 for dir in /usr/local/gnu/man \ 12 /usr/local/man /usr/man 13 do f=`echo $dir/cat$section/$1.*` 14 case $f 15 in *\*) 16 ;; *) found="$found $f" 17 esac 18 done 19 if [ -z "$found" ] 20 then 21 echo >&2 "`basename $0`: $1 not found" 22 exit=1 23 else files="$files $found" 24 fi 25 esac 26 shift 27 done 28 29 if [ "$files" ] 30 then cat $files 31 else echo >&2 "usage: `basename $0` [section] page ..." 32 exit=1 33 fi 34 exit $exit
Die Formatierung übernimmt normalerweise das Berkeley-Kommando catman das ungefähr folgendermaßen funktioniert:
1 #!/bin/sh 2 PATH=/usr/ucb:/bin:/usr/bin 3 4 for dir in /usr/local/gnu/man /usr/local/man /usr/man 5 do ( cd $dir 6 for i in 1 2 3 4 5 6 7 8 n l 7 do if [ -d man$i ] 8 then [ -d cat$i ] || mkdir cat$i 9 j=`ls -t cat$i | sed 1q` 10 ( cd man$i 11 case $j 12 in '') j=`ls` 13 ;; *) j=`find . -newer ../cat$i/$j -print` 14 esac 15 for j in $j 16 do nroff -man -u -h $j | 17 uniq | 18 sed 's/^ //' > ../cat$i/$j 19 done 20 ) 21 fi 22 done 23 ) 24 done
Kernighan und Pike führen vor, daß man einem Kommando wie cal eine elegantere Benutzeroberfläche geben kann:
1 #!/bin/sh 2 PATH=/usr/ucb:/bin:/usr/bin # sonst rekursiv... 3 4 case $# 5 in 0) 6 set `date`; m=$2; eval y=\$$# # cal heute 7 ;; 1) 8 m=$1; set `date`; eval y=\$$# # cal x Monat x im Jahr 9 ;; *) 10 m=$1; y=$2 # cal x y Monat x im Jahr y 11 esac 12 13 case $m 14 in [1-9] | 1[0-2]) # Monatszahl 15 ;; [0-9]*) y=$m; m= # Jahreszahl 16 ;; [jJ]an*) m=1 # Monat als Name 17 ;; [fF]eb*) m=2 18 ;; [mM]a[er]*) m=3 19 ;; [aA]pr*) m=4 20 ;; [mM]a[iy]*) m=5 21 ;; [jJ]un*) m=6 22 ;; [jJ]ul*) m=7 23 ;; [aA]ug*) m=8 24 ;; [sS]ep*) m=9 25 ;; [oO][ck]t*) m=10 26 ;; [nN]ov*) m=11 27 ;; [dD]e[cz]*) m=12 28 ;; *) echo >&2 "usage: `basename $0` [month [year]]" 29 exit 1 30 esac 31 32 exec cal $m $y
Den Fallverteiler kann man eleganter aufschreiben:
1 #!/bin/sh 2 PATH=/usr/ucb:/bin:/usr/bin # sonst rekursiv... 3 4 case $# 5 in 0) set `date`; m=$2; eval y=\$$# # cal 6 ;; 1) m=$1; set `date`; eval y=\$$# # cal x 7 ;; *) m=$1; y=$2 # cal x y 8 esac 9 10 while : 11 do case $m 12 in [1-9] | 1[0-2]) # Monatszahl 13 ;; [0-9]*) y=$m; m= # Jahreszahl 14 15 ;; *) for i in '1 an' '2 eb' '3 ar' \ 16 '3 ae' '4 pr' '5 ay' '5 ai' \ 17 '6 un' '7 ul' '8 ug' '9 ep' \ 18 '10 ct' '10 kt' '11 ov' \ 19 '12 ec' '12 ez' 20 do set $i 21 case $m 22 in ?$2*) m=$1 # Monatsname 23 break 2 24 esac 25 done 26 echo >&2 "usage: `basename $0` \c" 27 echo >&2 " [month [year]]" 28 exit 1 29 esac 30 break 31 done 32 exec cal $m $y
type zeigt zwar was die aktuelle Shell über einen Kommandonamen denkt, aber ein Shell-Skript wird normalerweise PATH selbst setzen. Kernighan und Pike führen ein Kommando which vor, das die Pfad-Suche simuliert:
1 #!/bin/sh
2
3 : ${1:?'no command name'}
4
5 for path in `echo $PATH | sed 's/^:/.:/
6 s/:$/:./
7 s/::/:.:/g
8 s/:/ /g'`
9 do if [ -x $path/$1 ]
10 then echo $path/$1
11 exit 0
12 fi
13 done
14 exit 1
Das Skript sollte mehrere Argumente erlauben und alle Fundstellen ausgeben:
1 #!/bin/sh 2 3 paths=`echo $PATH | 4 sed -e 's/^:/.:/' \ 5 -e 's/:$/:./' \ 6 -e 's/::/:.:/g' \ 7 -e 's/:/ /g'` 8 exit=1 9 10 for name 11 do for path in $paths 12 do [ -x $path/$name ] && exit=0 echo $path/$name 13 done 14 done 15 exit $exit
Ein Skript sollte grundsätzlich PATH setzen, um absichtliche oder unabsichtliche trojanische Pferde zu vermeiden. Außerdem sollte ein Argument mit / nicht gesucht werden. Ein Katalog ist kein nützliches Resultat. Letztlich besteht die Möglichkeit, daß test -x (noch) nicht verfügbar ist:
1 #!/bin/sh
2
3 paths=`echo $PATH |
4 PATH=/usr/ucb:/bin:/usr/bin \
5 sed -e 's/^:/.:/' -e 's/:$/:./' \
6 -e 's/::/:.:/g' -e 's/:/ /g'`
7 PATH=/usr/ucb:/bin:/usr/bin
8 exit=1
9
10 if [ -x /tmp ] 2> /dev/null # not every test has -x
11 then has_x=yes
12 else has_x=
13 fi
14
15 executable() { # path
16 if [ "$has_x" ]
17 then [ ! -d "$1" -a -x "$1" ]
18 else [ `expr "\`ls -l \"$1\" 2> /dev/null \
19 \`" : '-..x'` = 4 ]
20 fi
21 }
22
23 for name
24 do case $name
25 in */*)
26 executable "$name" && exit=0 echo "$name"
27 ;; *)
28 for path in $paths
29 do
30 executable "$path/$name" &&
31 exit=0 echo "$path/$name"
32 done
33 esac
34 done
35 exit $exit
Um am Schluß keinen Zeilentrenner auszugeben, benötigen manche Versionen von echo die Option -n, andere schließen den Text mit \c ab.
Die folgende Funktion beruht auf einer Idee von Skalla und ist portabel:
1 #!/bin/sh
2
3 prompt() { # arg ...
4 c=`echo '\c'`
5 n=; : ${c:+${n:=-n}}
6 c=; : ${n:-${c:=\\c}}
7 echo $n "$@"$c
8 }
9
10 [ prompt = `PATH=/usr/ucb:/bin:/usr/bin basename "$0"` ] && prompt "$@"
Man kann prompt auf verschiedene Arten aufrufen:
$ set a b c
$ . prompt; type prompt
prompt is a function
prompt(){
c=`echo '`
n=
: ${c:+${n:=-n}}
c=
: ${n:-${c:=}
echo $n "$@"$c
}
$ prompt a b c
a b c$ unset prompt; prompt a b c
a b c$ type prompt
prompt is hashed (prompt)
newer setzt einen exit-Code, der angibt, ob eine bestimmte Datei neuer als eine andere ist. Die Aufgabe geht auf Kernighan und Pike zurück, aber das Problem ist verblüffend schwierig zu lösen.
ls -t gibt seine Argumente zeitlich sortiert aus. Folglich könnte eine Lösung so aussehen:
1 #!/bin/sh
2 PATH=/usr/ucb:/bin:/usr/bin
3 set -f
4
5 if [ $# != 2 ]
6 then echo >&2 "usage: `basename $0` newfile oldfile"
7 exit 1
8 fi
9
10 ls -dt "$@" |
11 { read new && [ X"$new" = X"$1" ] && exit 0
12 exit 1
13 }
Leider funktioniert diese Lösung nicht, wenn eine der Argument-Dateien nicht existiert:
$ newer0 . a; echo $?; newer0 a .; echo $? a not found 0 a not found 1
Man muß offenbar zuerst den exit-Code von ls auswerten:
1 #!/bin/sh
2 # PATH=/usr/ucb:/bin:/usr/bin
3 set -f
4
5 if [ $# != 2 ]
6 then echo >&2 "usage: `basename $0` newfile oldfile"
7 exit 1
8 fi
9
10 if ls -dt "$@" > /dev/null
11 then ls -dt "$@" |
12 { read new && [ X"$new" = X"$1" ] && exit 0
13 exit 1
14 }
15 else exit 1
16 fi
Ohne eigenen PATH wird GNU-ls verwendet und die Lösung funktioniert. Setzt man PATH, stellt sich heraus, daß NeXT-ls den exit-Code 0 auch dann liefert, wenn ein Argument nicht existiert.
$ PATH=/bin sh -c './newer2 a .; echo $?; ./newer2 . a; echo $?' a not found a not found 1 a not found a not found 0
Vielleicht sollte man versuchen, find -newer zu verwenden:
1 #!/bin/sh 2 PATH=/usr/ucb:/bin:/usr/bin 3 set -f 4 5 if [ $# != 2 ] 6 then echo >&2 "usage: `basename $0` newfile oldfile" 7 exit 1 8 fi 9 10 test X"`find "$1" -newer "$2" -print | sed 1q`" = X"$1"
Alle bisherigen Lösungen funktionieren außerdem nicht besonders gut, wenn ein Dateiname mit einem Minuszeichen anfängt oder gar einen Zeilentrenner enthält.
1 #!/bin/sh 2 PATH=/usr/ucb:/bin:/usr/bin 3 set -f 4 5 if [ $# != 2 ] 6 then echo >&2 "usage: `basename $0` newfile oldfile" 7 exit 1 8 fi 9 10 test X"`ls -dt -- "$@"; echo .`" = X"$1 11 $2 12 ."
Der Aufruf von echo verhindet zwar, daß abschließende Zeilentrenner aus der Ausgabe von ls entfernt werden können, aber wenn Dateinamen nur aus Zeilentrennern bestehen, gibt es noch immer Probleme. Außerdem ist das Resultat auch dann wahr, wenn beide Dateien exakt gleich alt sind...
pick bietet Argumente zur Auswahl an und gibt die ausgewählten Argumente als Standard-Ausgabe aus:
1 #!/bin/sh 2 . 7.prompt 3 4 for arg 5 do prompt "$arg"; read x 6 case $x 7 in [yYjJ]*) echo "$arg" 8 esac 9 done
[Kernighan & Pike] schreibt die Idee Tom Duff zu. pick erlaubt interaktive Auswahl bei allen Kommandos:
$ pr `pick *.c` | lpr
So funktioniert die Lösung auch in einer Pipeline.
1 #!/bin/sh 2 . 7.prompt 3 4 for arg 5 do prompt >&2 "$arg" '? '; read x <&2 6 case $x 7 in [yYjJ]*) echo "$arg" 8 esac 9 done
So wählt man garantiert mit dem Terminal aus:
1 #!/bin/sh 2 . 7.prompt 3 4 for arg 5 do prompt >/dev/tty "$arg" '? '; read x </dev/tty 6 case $x 7 in [yYjJ]*) echo "$arg" 8 esac 9 done
So ist der Zugriff auf das Terminal billiger:
1 #!/bin/sh 2 . 7.prompt 3 4 exec 3>/dev/tty 4</dev/tty 5 6 for arg 7 do prompt >&3 "$arg" '? '; read x <&4 8 case $x 9 in [yYjJ]*) echo "$arg" 10 esac 11 done
Wenn - das einzige Argument ist, wird die Standard-Eingabe angeboten:
1 #!/bin/sh 2 . 7.prompt 3 4 case $# 5 in 0) exit 0 6 ;; 1) case "$1" 7 in -) while read arg 8 do prompt >&2 "$arg" '? '; read x <&2 9 case $x 10 in [yYjJ]*) echo "$arg" 11 esac 12 done 13 exit 0 14 esac 15 esac 16 17 for arg 18 do prompt >&2 "$arg" '? '; read x <&2 19 case $x 20 in [yYjJ]*) echo "$arg" 21 esac 22 done 23 exit 0 24
So beendet control-D die Auswahl:
1 #!/bin/sh 2 . 7.prompt 3 4 case $# 5 in 0) exit 0 6 ;; 1) case "$1" 7 in -) while read arg 8 do 9 if prompt >&2 "$arg" '? '; read x <&2 10 then 11 case $x 12 in [yYjJ]*) echo "$arg" 13 esac 14 else 15 echo 16 exit 0 17 fi 18 done 19 exit 0 20 esac 21 esac 22 23 for arg 24 do prompt >&2 "$arg" '? '; read x <&2 25 case $x 26 in [yYjJ]*) echo "$arg" 27 esac 28 done 29 exit 0
Mit einer Funktion ist das besser strukturiert:
1 #!/bin/sh
2
3 c=`echo '\c'`; n=; : ${c:+${n:=-n}}; c=; : ${n:-${c:=\\c}}
4
5 pick() { # arg ...
6 if echo >&2 $n "$1 ? "$c; read x <&2
7 then case $x
8 in [yYjJ]*) echo "$1"
9 esac
10 else echo
11 exit 0
12 fi
13 }
14
15 case $#
16 in 0) exit 0
17 ;; 1) case "$1"
18 in -) while read arg
19 do pick "$arg"
20 done
21 exit 0
22 esac
23 esac
24
25 for arg
26 do pick "$arg"
27 done
28 exit 0
bundle verpackt Textdateien so als Shell-Skript, daß sie am Ziel durch Ausführen des Shell-Skripts wiederhergestellt werden können:
1 #!/bin/sh 2 PATH=/usr/ucb:/bin:/usr/bin 3 4 for i 5 do echo "echo $i >&2" 6 echo "cat >$i << 'Ende von $i'" 7 cat $i 8 echo "Ende von $i" 9 done
Kernighan und Pike schreiben bundle Alan Hewett und James Gosling zu. Ehrgeizige Implementierungen erreichen fast die Fähigkeiten von tar.
Hier ist eine mittelprächtige Lösung ohne Funktionen, die Kataloge rekursiv bearbeitet, Zugriffsschutz berücksichtigt und mit wc eine Art Prüfsumme übermittelt:
1 #!/bin/sh 2 PATH=/usr/ucb:/bin:/usr/bin 3 bundle=`pwd`/bundle # for recursive call 4 exit=1 5 6 if [ -x /tmp ] 2> /dev/null # not every test has -x 7 then has_x=yes 8 else has_x= 9 fi 10 11 case $1 12 in -r) rflag=y; shift 13 ;; *) rflag=n 14 echo '# to unbundle set umask and sh this file' 15 tmp=/tmp/bundle$$ 16 echo 'exit=1 tmp=/tmp/bundle$$' 17 trap "trap 0; rm -f $tmp; 18 exit \$exit" 0 1 2 3 15 19 echo 'trap "trap 0; rm -f $tmp; 20 exit \$exit" 0 1 2 3 15' 21 echo 'exec > $tmp'; exec 3> $tmp 22 esac 23 24 for i 25 do if [ -d $i ] 26 then echo "[ -d $i ] || mkdir $i" 27 $bundle -r $i/* 28 elif [ -r $i ] 29 then echo "sed 's/^ //' > $i << 'End of $i'" 30 sed 's/^/ /' $i 31 echo "End of $i" 32 echo "wc $i"; wc $i >&3 33 if [ "$has_x" ] 34 then [ -x $i ] 35 else [ `expr "\`ls -l $i\`" : '...x'` = 4 ] 36 fi && echo "chmod +x $i" 37 else continue 38 fi 39 [ -w $i ] || echo "chmod -w $i" 40 echo "echo >&2 $i"; echo >&2 $i 41 done 42 43 case $rflag 44 in n) echo "diff -b - \$tmp << 'End of wc' >&2" 45 exec 3>&- 46 cat $tmp 47 echo 'End of wc' 48 exit=0 49 echo 'exit=$?' 50 esac
Die Lösung ist nicht sehr elegant, da sie sich selbst rekursiv aufruft. I bundle muß entweder auf PATH zu finden sein, oder man muß den Pfad bei der Installation explizit setzen. Außerdem wird relativ viel Code quasi verdoppelt. Dies kann man mit Funktionen vermeiden.
1 #!/bin/sh
2
3 usage() {
4 echo >&2 "usage: `basename $0` [-y] \c"
5 echo >&2 " file... dir... > bundle"
6 exit 1
7 }
8
9 if [ -x /tmp ] 2> /dev/null # not every test has -x
10 then has_x=yes
11 else has_x=
12 fi
13
14 case "$1"
15 in '') usage
16 ;; -y) yflag=-y; shift
17 [ $# = 0 ] && usage
18 ;; *) yflag=
19 esac
20
21 for i
22 do case "$i"
23 in *'
24 '* | *' '* | *' '* ) echo >&2 "$i: illegal filename"
25 exit 1
26 esac
27 done
28 argv="$*"
29
30 dup() { # arg ...
31 echo "$*"
32 eval "$@"
33 }
34
35 echo '# to unbundle set umask and sh this file'
36 echo '# specify a parameter to suppress queries'
37
38 dup PATH=/usr/ucb:/bin:/usr/bin
39 dup exit=1
40 dup tmp='/tmp/bundle$$'
41 echo 'yflag=$1'
42
43 dup 'trap "trap 0; rm -f $tmp; exit \$exit" 0 1 2 3 15'
44
45 dup 'ask() {
46 if [ "$yflag" ]
47 then echo >&2 $*
48 else if [ "`echo -n`" ]
49 then echo >&2 $* "? \\c"
50 else echo >&2 -n $* "? "
51 fi
52 if read x
53 then case "$x"
54 in [yYjJ]*) return 0
55 esac
56 else echo >&2
57 fi
58 return 1
59 fi
60 return 0
61 }'
62
63 dup 'exec 3> $tmp'
64
65 bundle() { # file...
66 ( for i
67 do if [ -d $i ]
68 then ask bundle $i || continue
69 echo "ask unbundle $i && {"
70 echo "[ -d $i ] || mkdir $i"
71 bundle $i/*
72 elif [ -r $i ] && [ `tr -d '[ -~]\11\12' < $i |
73 wc -c` = 0 ]
74 then ask bundle $i || continue
75 echo "ask unbundle $i && {"
76 echo "sed 's/^ //' > $i << 'End of $i'"
77 sed 's/^/ /' $i
78 echo "End of $i"
79 dup "wc >&3 $i"
80 if [ "$has_x" ]
81 then [ -x $i ]
82 else [ `expr "\`ls -l $i\`" : '...x'` = 4 ]
83 fi && echo "chmod +x $i"
84 else continue
85 fi
86 [ -w $i ] || echo "chmod -w $i"
87 echo '}'
88 done
89 ) }
90 bundle $argv
91
92 dup 'exec 3>&-'
93 echo 'diff >&2 -b - $tmp <<' "'End of wc'"
94 cat $tmp
95 echo 'End of wc'
96 dup exit=0
Dieses Kapitel beschäftigt sich mit Skripten, die in einem größeren Zusammenhang stehen.
Archivierung von Daten und Schutz vor gleichzeitig schreibendem Zugriff.
1 #!/bin/sh
2 #
3 # Eine Datei wird unter der Kontrolle von sccs verwaltet.
4 # Die Dateien finden sich unter
5 # ~umail/SCCS/`cat ~umail/SCCS/sub_dir`.
6 # ~umail/SCCS/sub_dir hat die als Inhalt eine Zeile
7 # der Form: 3.93.
8 #
9 # Kommandos:
10 # u_in: Bringt eine Datei unter Kontrolle von u_* (sccs)
11 # u_edit Man erhaelt eine Datei zum edieren
12 # u_get Man erhaelt eine Datei zum angucken
13 # u_info Man erhaelt Information ueber eine edierte Datei
14 # u_ls ls ueber alle mit u_* verwalteten Dateien
15 #
16 # Mon May 3 15:55:01 MET DST 1993, hp
17
18 . /home/umail/bin/shell_lib.a
19 USAGE="`basename $0`: `basename $0` file"
20
21 FILE= # einzupackende Datei
22 TARGET_DIR=$SCCS/`cat $SCCS_SUBDIR`
23 SAVE_DIR=$SCCS/`cat $SCCS_SUBDIR`/Save
24
25 case "`arch`"
26 in sun4)
27 ;; * ) fatal "rlogin to a sun4-architecture. Thanks"
28 esac
29
30 case "`basename $0`"
31 in "u_info")
32 ;; "u_ls")
33
34 ;; *) case $#
35 in 1) FILE="$1"
36 ;; *) fatal "$USAGE"
37 esac
38 esac
39
40
41 sccs_test_dir "$SCCS" # exist SCCS dir
42 sccs_test_file "$SCCS_SUBDIR" # current number
43 sccs_test_dir "$TARGET_DIR" # exist SCCS dir
44 #sccs_test_dir "$SAVE_DIR" # exist SAVE_DIR
45
46 case "`basename $0`"
47 in "u_in")
48 if [ ! -f $FILE ] # back with delta
49 then
50 fatal "$FILE didn't exist."
51 fi
52 if [ ! -r $FILE ] # back with delta
53 then
54 fatal "$FILE is read protected"
55 fi
56
57 if [ -f $TARGET_DIR/s.$FILE ] # back with delta
58 then
59 WORK=delta
60 else
61 WORK=create
62 echo "$FILE is new."
63 fi
64 cp $FILE $SAVE_DIR/$FILE.`date '+%y.%m.%d.%H.%M.%S'`
65 ;; "u_get")
66 WORK="get -k"
67 ;; "u_edit")
68 WORK=edit
69 ;; "u_info")
70 WORK=info
71 FILE=""
72 ;; "u_ls")
73 ( cd "$TARGET_DIR" && ls |
74 sed 's/^[sp]\.//' | sort -u )
75 exit 0
76 esac
77
78 {
79 sccs -p "$TARGET_DIR" $WORK $FILE << EOF
80 EOF
81 case "$WORK" # clean up
82 in "create"|"delta") if [ $? -eq 0 ]
83 then
84 rm -f ,$FILE $FILE
85 else
86 echo "Something failed."
87 fi
88 esac
89 } 2>&1 | fgrep -v "No id keywords"
90
shell_lib.a:
1 #!/bin/sh
2 #
3 # Shell_lib.a
4 #
5 # Variable:
6 #
7 PATH=:/usr/etc:/usr/local/bin:/etc:$PATH
8 PATH=/usr/bin:/home/umail/bin:$PATH
9 HOME=/home/umail
10 export HOME
11 SCCS=$HOME/SCCS
12 SCCS_SUBDIR=$HOME/SCCS/sub_dir
13
14 #
15 # Functions:
16 #
17 fatal() # message
18 { echo >&2 `basename $0`: "$@"
19 exit 1
20 }
21
22 test_and_create_dir() # dir
23 { if /usr/bin/test ! -d $1
24 then
25 echo "Warning: $1 not exists."
26 mkdir $1
27 chmod 770 $1
28 chmod g+s $1
29 fi
30 }
31
32 sccs_test_dir() # dir
33 { if /usr/bin/test ! -d $1
34 then
35 echo "Warning: $1 not exists."
36 mkdir $1
37 chmod 770 $1
38 chmod g+s $1
39 fi
40 if /usr/bin/test ! -w $1 # write protected?
41 then
42 fatal "$1 is write protexted. Call for help"
43 fi
44
45 }
46
47 sccs_test_file() # dir
48 { if /usr/bin/test ! -f $1 # current version
49 then
50 fatal "$1 didn't exist. Call for help"
51 fi
52 if /usr/bin/test ! -r $1 # read protected
53 then
54 fatal "$1 is read protected. Call for help"
55 fi
56 }
Man kann auch mit der sh(1), archivieren. Es gibt allerdings Probleme, wenn die Dateien binäre Daten enthalten.
1 : Bourne Shell 2 # bundle -- 1.2 Jun 22 06:17:04 1987 3 # Copyright (c) 1987 Axel T. Schreiner 4 5 # bundle file... directory... 6 7 tmp=/tmp/bundle$$ 8 9 case $1 10 in -r) rflag=y; shift 11 ;; *) rflag=n 12 echo ': to unbundle set umask and sh this file' 13 echo 'trap "rm -f /tmp/bundle$$" 1 2 3 15' 14 echo 'exec > /tmp/bundle$$'; exec 3> $tmp 15 esac 16 17 for i 18 do echo "echo >&2 $i"; echo >&2 $i 19 if [ -d $i ] 20 then echo "[ -d $i ] || mkdir $i" 21 bundle -r $i/* 22 else echo "sed 's/^ //' > $i << 'End of $i'" 23 sed 's/^/ /' $i 24 echo "End of $i" 25 echo "wc $i"; wc $i >&3 26 [ -x $i ] && echo "chmod +x $i" 27 fi 28 [ -w $i ] || echo "chmod -w $i" 29 done 30 31 case $rflag 32 in n) echo "diff -b - /tmp/bundle\$\$ << 'End of wc' >&2" 33 exec 3>&- 34 cat $tmp; rm $tmp 35 echo 'End of wc' 36 echo 'rm -f /tmp/bundle$$' 37 echo 'exit 0' 38 esac
Nur einer darf eine Datei edieren. (vim ist Voraussetzung).
1 #!/bin/sh 2 3 USAGE="vim: vim file" 4 5 case $# 6 in 1) if [ -f "$1".swp ] 7 then 8 echo > /dev/tty "$1 is under construction." 9 else 10 vim "$1" 11 fi 12 ;; *) echo > /dev/tty $USAGE 13 exit 1 14 esac 15 exit 0
ftp zu einer bestimmten Zeit.
1 #!/bin/sh
2 # (c) afb SAI Uni Ulm
3 # adapted gsk FB6 Uni Osnabrueck
4 # adapted hpb FB6 Uni Osnabrueck
5 #
6 # Zweck: Aufruf von ftp, wobei die Kommandos, die ftp remote
7 # ausfuehren soll, auf der Kommandozeile mitgegeben
8 # werden koennen bzw. von stdin kommen.
9 #
10 # Optionen:-s seconds: Bevor der ftp aufruf erfolgt,
11 # seconds Sekunden warten.
12 # -f path path wird von ls und get verwendet
13 # -ls: ls-Listing von path
14 # -get: get von path
15 # -cat: die Kommandos werden von stdin erwartet.
16 # host: ftp-Host
17
18 PATH="/usr/local/gnu/bin:/usr/ucb:/usr/bin:/bin:/etc:/usr/etc"; export PATH
19 MYHOST=`hostname`
20 : ${MYHOST:=jupiter}
21 echo $MYHOST | grep '\.' > /dev/null || \
22 MYHOST=`arp $MYHOST | sed 's/.*(\(.*\)).*/\1/'`
23 # originally "nsquery" was used to
24 # determine the full name of the
25 # requesting host, but here (OS)
26 # "nsquery" is not installed.
27
28
29 : ${ANONYM:=anonymous}
30 : ${PASSWD:=${LOGNAME:-`whoami`}@} #${MYHOST}}
31
32 Sleeping=0 # sleep 0 seconds before ftp ...
33 Cmd=ls # default cmd
34 Cmd_line=ls # default cmd_line
35 Ftphost=dione # default ftp-host
36 Path=/ # default path
37 File= # default filename
38 Flag_counter=0 # > 1 --> ls, get, cat exclusive !!
39
40 #
41 # local funtions
42 #
43 fatal()
44 {
45 echo "fatal: `basename $0` [-s sec] [-ls|-get] [-f path] [-cat] host"
46 if [ $# -gt 0 ]
47 then
48 echo "fatal: $1"
49 fi
50 echo " defaults: cmd = ls"
51 echo " defaults: seconds = 0"
52 echo " defaults: host = $Ftphost"
53 exit 1
54 }
55
56
57 # some abbreviations (for nameserver
58 # sometimes does not work correctly)
59 while [ $# -gt 0 ]
60 do
61
62 case "$1"
63 in "")
64 ;; -v*) fatal # --> usage & exit
65
66 ;; -ls) Cmd=ls; # listing only
67 Flag_counter=`expr $Flag_counter \+ 1`
68
69 ;; -get) Cmd=get; # get file --> mode == I
70 Flag_counter=`expr $Flag_counter \+ 1`
71
72 ;; -cat) Cmd=cat; # cat -- read from stdin
73 Flag_counter=`expr $Flag_counter \+ 1`
74
75 ;; -f) shift;
76 Path=`dirname $1` # split file &
77 File=`basename $1` # path
78
79 ;; -s) shift; Sleeping=$1
80 if [ $Sleeping -lt 0 ]
81 then
82 fatal "seconds > 0 !!!"
83 fi
84
85 ;; -*) fatal "unknown option: $1"
86 ;; *) if [ $# -eq 1 ]
87 then
88 Ftphost="$1"
89 else
90 fatal "only one host."
91 fi
92 esac
93
94 shift
95 done
96
97 # only one cmd will be accepted
98 if [ $Flag_counter -gt 1 ]
99 then
10 fatal "ls, get and cat, ooohhhhhhh!!!"
10 fi
10
10 case $Cmd
10 in cat) Cmd_line1="cat"
10 Cmd_line2=
10 ;; *) Cmd_line1="echo cd $Path"
10 Cmd_line2="echo $Cmd $File"
10 esac
10
11
11 which ping
11 ping $Ftphost 1 1 > /dev/null
11
11 case $?
11 in 0) break; # host is reachable
11 ;; *) fatal "host is not reachable"
11 esac
11
11 sleep $Sleeping
12
12 { echo open $Ftphost
12 echo user $ANONYM "\"$PASSWD\""
12 echo binary # ok?
12 eval $Cmd_line1
12 eval $Cmd_line2
12 echo bye
12 } | ftp -niv
12
12 exit $?
1 #!/bin/sh
2 # (c) hpb, Sat Aug 31 12:33:42 MET DST 1991
3 #
4
5 usage()
6 {
7 echo "`basename $0`: `basename $0` [-D dict] [-d delete] [-a add_on] file"
8 echo "---------------------------------------------------------"
9 echo " Vergleicht alle Woerter der Eingabedatei (ASCII oder troff-Text)"
10 echo " mit einem Woerterbuch."
11 echo " Alle Woerter, die im Woerterbuch nicht"
12 echo " enthalten sind, werden auf stdout ausgegeben."
13 echo ""
14 echo " Einbuchstabige, zweibuchstabige, dreibuchstabigen Worte"
15 echo " und Worte die mit einem Punkt beginnen"
16 echo " werden entfernt."
17 echo " Alle Worte die mit einem Punkt beginnen werden entfernt."
18 echo ""
19 echo " Existiert eine Datei 'add_on' wird diese zum"
20 echo " Woerterbuch hinzugenommen."
21 echo ""
22 echo " Alle Worte die in der Datei 'delete' enthalten sind,"
23 echo " werden nicht ausgegeben."
24 echo "---------------------------------------------------------"
25 }
26
27 TMP=/tmp/`basename $0`.$$
28 TMP_WDB=/tmp/wdb.$$
29 WDB=$HOME/bin/dict
30 ADD_ON=add_on
31 DELETE=delete
32 INPUT_FILES=" "
33 PROG=`basename $0`
34
35 while :
36 do case $1
37 in -D) shift; WDB=$1
38 ;; -d) shift; DELETE=$1
39 ;; -a) shift; ADD_ON=$1
40 ;; -*) usage; exit 1
41 ;; *) break
42 esac
43 shift
44 done
45
46 if [ ! -f $WDB ]
47 then
48 echo "$PROG: Woerterbuch ($WDB) existert nicht"
49 exit 1
50 fi
51
52 if [ ! -f $ADD_ON ]
53 then
54 echo "$PROG: Warning: Lokales Woerterbuch ($ADD_ON) existert nicht" >&2
55 ADD_ON=
56 fi
57
58 if [ ! -f $DELETE ]
59 then
60 echo "$PROG: Warning: spezielles Woerterbuch ($DELETE) existert nicht" >&2
61 DELETE=
62 fi
63
64
65 case $# # Mindestens eine Datei muss vorhanden sein
66 in 0) usage;
67 exit 2
68 esac
69
70 while : # alle Eingabedateien müssen existieren.
71 do
72 case $1
73 in '') break
74 esac
75
76 if [ ! -f "$1" ]
77 then
78 echo "$PROG: $1 existiert nicht!"
79 echo "$PROG: bye bye."
80 exit 1
81 else
82 INPUT_FILES="$INPUT_FILES $1"
83 shift
84 fi
85 done
86
87 cat $INPUT_FILES | sed 's/\\f(CW//g
88 s/\\f[123456789P]//g
89 s/\\(hy//g
90 s/\\(<<//g
91 s/\\(>>//g
92 s/\\\*\[//g
93 s/\\\*$//g
94 s/\\s[+-][0-9]//g
95 s/\\s0//g' \
96 | /usr/bin/tr '[()[]{},;:~"!@$%^&<>/ ] ' '\012' \
97 | grep -v '^\.' | grep -v '^.$' \
98 | /usr/bin/tr '\.' '\012' | grep -v '^$' \
99 | grep -v '^..$' | grep -v '^...$' \
10 | grep -v '^.$' \
10 | sort -u > $TMP
10
10 cat $DELETE $ADD_ON $WDB | sort -u > $TMP_WDB
10
10 comm $TMP $TMP_WDB | grep -v ' '
10
10 rm -f $TMP $TMP_WDB
10 exit 0
1 #!/bin/sh
2 #
3 # Mit diesem Skript soll protokolliert werden koennen,
4 # aus welchem Grund ein Rechner stehen blieb.
5 #
6 # Aufruf ---> vi
7 # editier den Inhalt
8 # :wq
9 # die Datei wird via mail verteilt.
10 #
11 # hp, Mon Feb 14 08:54:43 MET 1994
12 # ADMIN=problems ---> ADMIN=sys Thu Jul 21 16:06:48 MET DST 1994 - hp
13
14
15 USAGE="`basename $0` hostname"
16 : ${SHLIB:=/usr/local/lib/shf}
17 . ${SHLIB}/setPATH
18 TMP_FILE=/tmp/`basename $0`.$$
19 REASON=
20 HOST=
21 ADMIN=bischof
22
23 #
24 # Functions:
25 #
26 fatal() # message
27 { echo >&2 `basename $0`: "$@"
28 exit 1
29 }
30
31 create_file() # file
32 { touch "$1" 2> /dev/null
33 [ $? -eq 0 ] || fatal "Can't create $1 for writing."
34 }
35
36 trap 'trap "" 0 1 2 3 13 14 15;
37 rm -f "$TMP_FILE";
38 exit' 0 1 2 3 13 14 15
39
40
41 case $#
42 in 1) REASON="Absturz von $1"
43 HOST="$1"
44 break
45 ;; *) fatal $USAGE
46 esac
47
48 case `whoami`
49 in "root") fatal "Don't use the root login for this work."
50 esac
51
52 create_file $TMP_FILE
53
54 cat << EOF > $TMP_FILE
55 Protokoll ueber einen Rechnerabsturz
56 =====================================
57
58 Rechner : $HOST
59 Date : `date`
60 Knowledge Person: `who am i`
61
62 =====================================
63
64 Grund : XX
65 /usr/adm/messages:
66 Vorgehensweise :
67
68
69 EOF
70
71 vi +/XX $TMP_FILE
72
73 /usr/ucb/mail -s "$REASON" $ADMIN < $TMP_FILE
74
Können Sie den Zeitpunkt schon erkennen, an dem Ihre über's Netz verstreuten Dateisysteme mit dem bisherigen Konzept nicht mehr zu sichern sind? Uns ging es ebenso. Weil kommerzielle Systeme zu teuer waren, entwickelte ich mit existenten Werkzeugen, wie awk, rsh, rdump und der Bourne-Shell, einen simplen Mechanismus, mit dem wir unseren Backup realisieren.
In unserem heterogenen UNIX-Netz, bestehend aus NeXTen, Sun3s, Sun4s und einer Celerity, sind ca. 70 Dateisysteme mit etwa 7 GB an Datenvolumen zu sichern. Davon sind ca. 4 GB Benutzerdaten, die täglich, und ca. 3 GB Systemdaten, die einmal wöchentlich gesichert werden sollten. Als Backup-Medium steht ein Exabyte mit 5 GB fassenden Bändern zur Verfügung.
Da sich in unserem Netz die Struktur der Dateisysteme semesterweise ändert, muß der Mechanismus leicht an jede wahrscheinliche Konfiguration anpaßbar sein. In Zukunft wird sich in unseren Rechner-Zoo noch eine weitere Gattung einschleichen, was bedeutet, daß der Mechanismus keine speziellen Eigenschaften des bestehenden Netzes nutzen kann. Damit der Betrieb tagsüber ungestört ist, muß der Backup nachts und demzufolge ohne Bedienung als Batch-Job ablaufen.
Weil wir Rechnerbetrieb als Hobby betreiben, stand für die Entwicklung sehr wenig Zeit zur Verfügung. Um den Entwicklungsaufwand in Grenzen zu halten, wurden wann immer möglich, existente Programme eingesetzt. Die reine Entwicklungszeit betrug ca. 8 Stunden.
Das Backup-Skript wird vom Benutzer backup auf dem Rechner, an dem das Exabyte physikalisch angeschlossen ist, gestartet. Durch den Inhalt der Datei dump_table wird gesteuert, welche Dateisysteme von welchen Rechnern an welchem Tag gesichert werden sollen, siehe Abbildung 1.
$ head dump_table [1] thor:/dev/root [1] thor:/dev/usr [02-6] thor:/dev/export [02-6] thor:/dev/home [1] thor:/dev/l_export [1] iduna:/dev/usr [02-6] iduna:/dev/export [1] frigga:/dev/root [1] frigga:/dev/usr /usr [02-6] frigga:/dev/export [1] garm:/dev/root
Die erste Spalte von dump_table gibt an, an welchen Tagen das in der zweiten Spalte stehende physikalische Dateisystem gesichert werden soll. Als Indikatoren für den Wochentag wurden Ziffern gewählt, um die Datei übersichtlich zu halten und Bereichsangaben leichter mit awk bearbeiten zu können. Für date +%w beginnt die Woche mit dem Tag 0 am Sonntag.
Diese Datei muß unter allen Umständen mit dem Zustand des Netzes übereinstimmen, was die Verbindung zwischen Montagepunkt des Dateisystems und dem entsprechenden Rechner betrifft. Die Daten, die dieser Datei zugrunde liegen, sind auf dem Netz, wenn auch verstreut, vorhanden. c_dump_t sammelt die einzelnen /etc/fstabs der Rechner unseres Netzes auf und generiert dump_table, siehe Abbildung 2.
#!/bin/sh
# c_dump_t - generiert eine Rohversion der Tabelle,
# nach der backup sichert.
#
. shell_lib.a # Globale Variablen & fatal & test_...
usage="usage: `basename $0`" # Aufruf
DUMP_TABLE=${DUMP_TABLE}.new # pro Zeile ein Eintrag
case "$#"
in 0) break;
;; *) fatal "$usage"
esac
# Falls $0 zweimal zur gleichen Zeit laeuft, gibt's Aerger.
/etc/link "$HOME/bin/`basename $0`" "$LOCK" ||
fatal "`basename $0` in use; try again"
trap 'rm -f "$LOCK"; exit' 0 1 2 3 13 14 15 # Aufraeumaktionen
test_and_create_dir $FSTABS # Falls nicht vorhanden generieren
hosts=`gethostname "inf"` # alle Rechner der Netzgruppe 'inf'
for i in $hosts # alle fstabs aufsammeln
do
rcp $i:/etc/fstab $FSTABS/$i # wegen grep
case $?
in 1) fatal "$0: \"rcp $i:/etc/fstab $FSTABS/$i\" failed"
;; 0) chmod 666 $FSTABS/$i # wegen Ueberschreiben
esac
done
cd $FSTABS
# [\tBlank]
grep "^\/dev\/" * | sed 's/[ ].*//' >> $TOP/$DUMP_TABLE
exit 0
Dadurch ist eine Inkonsistenz zwischen dem Zustand des Netzes und dump_table nahezu ausgeschlossen.
Um Funktionen und Werte, die in mehreren Skripten verwendet werden nur an einer Stelle pflegen zu müssen, werden diese in eine Shell-Bibliothek ausgelagert. Diese Bibliothek wird in den entsprechenden Skripten durch das .-Kommando ausgewertet, siehe Abbildung 3.
#!/bin/sh
#
# shell_lib.a
#
TOP=/home/backup # Katalog
FSTABS=$TOP/Fstabs # Die Fstabs aller Rechner
LOCK=$TOP/.lock # entweder backup oder c_dump_t
DUMP_TABLE=$TOP/dump_table # pro Zeile ein Eintrag
TAPE=/dev/nrst1 # das Exabyte
HEADER=header
#
fatal() # message
{ echo >&2 `basename $0`: "$@"
exit 1
}
test_and_create_dir() # dir
{ if [ ! -d $1 ]
then
echo "Warning: $1 does not exist."
mkdir $1
fi
}
dump_table ist die einzige Datei, die vom Systemadministrator gepflegt werden muß. Die Arbeit beschränkt sich allerdings auf die Festlegung, an welchem Tag ein Dateisystem gesichert werden soll. Die einfache Struktur dieser Datei verringert die Gefahr eines fehlerhaften Eintrags.
Das backup-Skript läuft auf dem Exabyte-Server mit den Berechtigungen eines normalen Nutzers. Würde man das Skript als root starten, müßte der Exabyte-Server für jeden Rechner, dessen lokale Platte gesichert werden soll, als vertrauenswürdig erscheinen. Dies erschien mir als unnötig und zu risikoreich.
Der Algorithmus des Skripts ist trivial:
Für jede Zeile von dump_table wird auf dem
entsprechenden Rechner
ein rdump-Kommando
der Form
/etc/rdump ${LEVEL}ufs $EXA_SERVER:/dev/nrst1
mit root-Berechtigung abgesetzt.
Ist dump_table abgearbeitet,
wird verifiziert,
ob der Backup für alle Dateisysteme erfolgreich war,
falls nicht,
wird der Systemadministrator via mail informiert.
Wie sorgt man nun dafür, daß rdump auf den unterschiedlichen Architekturen unter root-Berechtigungen abläuft? Mit dem dazwischen geschaltenen Shell-Skript execS, siehe Abbildung 4.
#!/bin/sh
#
# execS fuehrt $@ unter euid = uid = 0
# auf Sun[34], NeXT oder Celerity aus.
#
# Beware of:
# -rwsr-xr-x 1 root 106496 Jan 18 11:57 *equal
# ....
PATH=:/usr/lbin:/usr/bin:$HOME/bin:/home/backup/bin:$PATH
case `arch`
in "sun4") echo " $@" | $HOME/bin/Sun4equal; break
;; "sun3") echo " $@" | $HOME/bin/Sun3equal; break
;; "NeXT") echo " $@" | $HOME/bin/Nextequal; break
;; "celerity") echo " $@" | $HOME/bin/Celerityequal; break
;; *) exit 1 # Generiere *equal aus .../Src/equal.c
esac
Abhängig von der Architektur aktiviert execS ein kleines C-Programm *equal, das die effektive und wirkliche Benutzernummer auf 0 setzt, mit execl, die Shell aufruft, die dann von Standardeingabe das entsprechende Kommando liest und abarbeitet, siehe Abbildung 5.
/*
* setzt die euid = uid = 0.
*/
#include <stdio.h>
#include <sys/types.h>
#include <pwd.h>
#include <strings.h>
#define BACKUP "backup"
main()
{
uid_t uid;
uid_t euid;
struct passwd * pp;
if ( ! (pp = getpwuid(getuid()) ) ) {
fprintf(stderr," getpwuid failed\n");
exit(1);
}
if ( strcmp(pp->pw_name, BACKUP ) )
exit(1);
if ( setreuid(0,0) == -1 ) {
fprintf(stderr," setregid failed\n");
exit(1);
}
execl("/bin/sh", "/bin/sh", (char *)0);
}
Um das Sicherheitsloch in Grenzen zu halten, überprüft *equal wer der Aufrufende ist. Bei jedem anderen als backup terminiert das Kommando vor Ausführung des kritischen Aufrufs.
Es reicht nicht, nur die effektive uid auf 0 zu setzen, da Suns rdump überprüft, ob uid = euid ist. Deshalb genügt es nicht, eine Kopie von /bin/sh mit den entsprechenden Rechten auszustatten.
Für die kurze Zeit des Kommunikationsaufbaus wird auf dem Exabyte-Server arrangiert, daß der Rechner dessen Dateisystem als nächstes gesichert werden soll, als vertrauenswürdig gilt.
Der wesentliche Teil von backup ist in Abbildung 6 abgebildet.
ex_dump_l $DUMP_TABLE | \
sed 's/[ ].*//' | \
sed 's/:/ /' | \
while read Host Rdev
do
rsh -n $Host $HOME/bin/execS $DumpCmd ${LEVEL}ufs \
$Dumphost:$TAPE $LENGTH $Rdev
done
ex_dump_l extrahiert die an diesem Tag zu sichernden Zeilen.
Wir sichern prinzipiell alle Daten der Dateisysteme. Inkrementelle Sicherungen bringen uns keinen Vorteil, da auf alle Fälle ein Band benötigt wird, das bisher genügend Platz für einen kompletten Backup bieten. Da die Sicherung von 4 GB Daten ungefähr 6 Stunden dauert, reicht die Nacht zum Sichern der Daten aus. Die Restaurierung verlorengegangener Daten ist für uns aus vollständigen Sicherungen einfacher, als wenn wir inkrementell sichern würden. Das Skript wird an allen Arbeitstagen von Hand gestartet. In Abbildung 7 ist ein typischer Ablauf abgebildet.
loki backup 72 backup Tape number = 20 Sleep for ?? seconds: 15000 I hope 15000 is ok. loki backup 72
Von jedem beschriebenen Band existiert eine Datei, in welcher der Verlauf des Backups protokolliert ist. Auftretende Fehler können so analysiert und falls möglich behoben werden.
In einer zweiten Datei stehen mt-Anweisungen, mit denen man bis zu der Stelle, an der das gesicherte Dateisystem zu finden ist, vorspulen kann, siehe Abbildung 8.
On Volume: 20 ======================== mt -f /dev/nrst1 fsf 0 DUMP echo thor:/dev/export ------------- backup on sun4 was ok mt -f /dev/nrst1 fsf 1 DUMP echo thor:/dev/home ------------- backup on sun4 was ok mt -f /dev/nrst1 fsf 2 DUMP echo dosuni:/dev/export ------------- backup on sun4 was ok ...
Diese Anweisungen erleichtern ein Restaurieren erheblich, denn auf einem Band können bis zu 40 Dateisysteme gesichert sein. Die eigentliche Restaurierung muß via restore in die Wege geleitet werden. Da dies bei uns selten vorkommt, erschien mir eine weitere Unterstützung unnötig.
In aller Regel funktioniert unser Backup problemlos. Ab und zu blockiert unser Exabyte den SCSI-Bus des Exabyte-Servers, was dann dazu führt, daß manuell eingegriffen werden muß. Dies ist allerdings ein Problem das weniger auf den Backup-Mechanismus, als vielmehr auf das Exabyte zurückzuführen ist.
Was uns noch fehlt, ist ein Programm, das die Bandverwaltung übernimmt, damit Verwechslungen von Bändern ausgeschlossen werden können.
Der Mechanismus hat sich bei uns bewährt. Der Aufwand an menschlicher Arbeitskraft, die bisher nötig war, um den Backup zu ziehen, wurde wesentlich reduziert. Die Entwicklungszeit hat sich um ein Vielfaches ausbezahlt. Die fehlende Graphikoberflächen, die man sich denken kann, wurde bisher noch nicht vermißt.
Hat man eine Anzahl von Unix-Rechnern vernetzt, dann kann man die vorhandenen Ressourcen optimal ausnutzen, falls man auf jedem beliebigen Rechner ein Kommando mittels rsh ohne Eintippen des Paßworts aktivieren kann. Ist Ihr System so konfiguriert? Falls ja, haben Sie jedem Einbrecher, der sich für Ihr Netz interessiert, den goldenen Schlüssel zum Öffnen in die Hand gegeben. Warum dies so ist und was man dagegegen unternehmen kann, wird in diesem Artikel dargelegt.
Ist man auf einem Rechner, nennen wir ihn mozart, angemeldet, und möchte auf thor ein Kommando wie z.B. date absetzen, wird in punkto Sicherheit der in Abbildung 1 dargestellte Algorihmus angewendet.
![[picture]](one_file-1.gif)
Abbildung 1: Kontaktaufnahme
Der fremde Rechner überprüft, ob das Tupel (loginname, Rechner) berechtigt ist, Kommandos auf ihm zu aktivieren. Er beantwortet die Frage, indem er eine lokale Datenbasis zu Rate zieht. Falls ja, wird das Kommando ausgeführt; falls nein, wird die Ausführung des Kommandos verweigert.
Wann ist ein fremder Rechner in Verbindung mit einer loginname vertrauenswürdig? Das Vertrauensverhältnis kann auf zwei verschiedenen Wegen definiert werden.
Nehmen wir an, im Netz gibt es wenigstens die beiden Rechner balrog und gandalf und alle Nutzer gelten auf allen Rechner als vertrauenswürdig. Ein Bösewicht, der Zugang zum Netz hat, bringt seinen Laptop mit, steckt diesen auf das Netz und gibt ihm die gleiche IP-Adresse wie balrog. Dann meldet er sich als superuser oder ein anderer interesanter Nutzer auf balrog an. Da dies sein Rechner ist, dürfte ihm das entsprechende Paßwort wohl bekannt sein. Mit rsh gandalf erlangt er superuser-Rechte auf einem Rechner des Netzes, ohne daß er das entsprechende Paßwort kennt. Vorbei ist es mit der Sicherheit der Daten.
Weil dieser Aspekt nicht sicher zu bekommen ist, werden von fast allen Administratoren die systemweiten rhost-Dateien gelöscht. Die Arbeit auf dem Netz wird unbequemer, vieles dauert länger und wird demzufolge teurer.
Angenommen der Heimatkatalog eines Nutzers und seine user id auf allen Rechnern des Netzes sind gleich, und $HOME/.rhosts ist leer. Betrachten wir nochmals Abbildung 1: Nur zum Zeitpunkt der Kontaktaufnahme der beteiligten Rechner wird das Vertrauensverhältnis geprüft -- also legen wir die Datei $HOME/.rhosts kurz vor der Kontaktaufnahme an und löschen sie zum fühest möglichen Zeitpunkt wieder. Siehe Abbildung 2.
#!/bin/sh
RHOSTS=$HOME/.rhosts
if [ --f $RHOSTS ]
then
echo "$RHOSTS exists."
fi
echo `hostname` > $RHOSTS
rsh $1 "rm --f $RHOSTS 2> /dev/null; $2"
exit 0
Abbildung 2: Vetrauen ist gut, kein Vertrauen ist besser.
Nur für die Zeitdauer zwischen dem Füllen von $HOME/.rhosts und dem Löschen ist die Benutzerkennung unsicher. Es ist klar, daß das Skript noch zusätzliche Arbeit in puncto Environment und Pfaden leisten muß.
Unberechtigterweise in ein gut gepflegtes Unix System einzudringen ist, ohne Kenntnis eines entsprechenden fremden Paßworts, sehr schwierig. Aus diesem Grunde konzentrieren sich die meisten Attacken der †bösen Buben† darauf, fremde Paßwörter in ihren Besitz zu bringen.
Die Gegenspieler der †bösen Buben† sind einerseits der Systemadministrator, der durch komplexe Maßnahmen versucht, die Entfaltungsmöglichkeit dieser †bösen Buben† zu erschweren, und andererseits der Nutzer, indem er †vernünftige† Paßwörter wählt und diese in regelmäßigen Abständen ändert.
Angriffe von außen, d.h. der Versuch in ein fremdes Netz einzudringen, setzen sehr großes Wissen voraus und sind aufgrund von Sicherheitsmaßnahmen der Administration in aller Regel zum Scheitern verurteilt.
Ist man allerdings in einem Netz und versucht ein fremdes Paßwort in Erfahrung zu bringen, sind die Karten gar nicht so schlecht. Für den Artikel gehen wir vom zweiten Fall aus.
Prinzipiell bieten sich folgende Wege an: Der erste, etwas langwierige Weg besteht darin, für einen bestimmten Nutzer alle Paßwörter auszuprobieren, die er haben könnte, indem man sie eintippt. Dies sieht dann in etwa so aus:
mozart% login login: bischof Password: Login incorrect login: bischof Password: Login incorrect login: ...
Berechnen wir die Anzahl der Möglichkeiten, die auszuprobieren sind. Wenn wir annehmen, daß ein Paßwort zwischen vier und acht Zeichen lang ist und aus 95 verschiedenen Zeichen (Leerzeichen bis †~† bestehen kann, errechnet sich die Anzahl der verschiedenen Möglichkeiten durch
![[equation]](one_file-2.gif)
Nehmen wir an, daß man zum Eintippen eines Paßworts im Durchschnitt 5 Sekunden benötigt, so hat man nach ca. 1077800436 Jahren alle Paßwörter ausprobiert. Betrachtet man im Vergleich dazu das Alter der Erde, welches ca. 5 Milliarden Jahre beträgt, dann sieht man deutlich, daß dieser Weg dem †bösen Buben† etwas Geduld abverlangt.
Der zweite Weg besteht darin, den Rechner die Paßwörter generieren und durch einen login-Versuch testen zu lassen. Das Erfinden geht sicher unheimlich schnell, aber da login bei einem falschen Paßwort kurz einnickt, bevor er einen erneuten login-Versuch akzeptiert, ist dieser Weg bestimmt bequemer als der erste Vorschlag, aber nicht wesentlich schneller als derselbe.
Folgende Überlegung könnte die Sache etwas beschleunigen: Wie funktioniert eigentlich login? login liest das eingetippte Paßwort ein, verschlüsselt es und vergleicht das verschlüsselte Paßwort dann mit dem Paßworteintrag des Nutzers. Sind die beiden ungleich, wird der Anmeldeversuch abgewehrt, ansonsten findet die Anmeldung statt.
Soweit die Überlegungen, nun gehts in die Praxis. Die Verschlüsselung erfolgt mittels char *crypt(key, salt). crypt(3) nimmt ein Wort (key) und einen Initialwert (salt) und liefert das verschlüsselte Wort zurück. Ist das verschlüsselte Wort und der Paßworteintrag gleich, hat man das Paßwort gefunden. Das einzige Problem besteht nur in der richtigen Wahl von salt. salt besteht aus den ersten zwei Buchstaben des Paßworts. Abbildung 1 zeigt ein Programm,
/*
* Ein Wort in Klartext wird mit crypt verschluesselt,
* und das Resultat mit dem Passworteintrag verglichen.
*
* Passworteintrag: bischof:ei1/r7g1wRyAI:106:11:Hans\(emPeter ...
* Passwort: dmva1m10
*
*/
#include <stdio.h>
void main(void) {
char * pwd = "dmva1m10";
char * pwd_entry = "ei1/r7g1wRyAI";
char salt[] = { pwd_entry[0], pwd_entry[1], '\0' };
printf("crypt: %s\n", crypt(pwd, salt) );
printf("pwd_entry: %s\n", pwd_entry );
exit(0);
}
Abbildung 1: Gewußt wie
Ein Ablauf des Programms liefert:
mozart Src 178 crypt_1 crypt: ei1/r7g1wRyAI pwd_entry: ei1/r7g1wRyAI
Somit haben wir alle Ingredienzen, um den zweiten Weg entscheidend zu verkürzen. Ein Verschlüsselungs- und Testvorgang benötigt auf einer Sparc 10 ca. 0.012 Sekunden. Nach ca. 12933605 Jahren hat unser Programm alle Möglichkeiten ausprobiert und ein Paßwort entschlüsselt. Auch Transputersysteme oder andere schnellere Rechner können das Problem wohl nicht in einer adäquaten Zeit lösen.
Ein Punkt wurde bisher nicht berücksichtigt: die Psychologie. Die meisten Nutzer nehmen als Paßwort nicht eine beliebige Buchstabenkombination, sondern ein Wort, das sie sich leicht merken können, z.B. eine Autonummer (OSJ392), den Namen einer Person aus einem Buch (gandalf), den Namen ihres Lieblingsinstruments (trompete), den Anfangsbuchstaben der Worte eines berühmten Spruchs (aus Goethes Faust, Hexenszene: Du mußt verstehen, aus eins mach zehn ... ↔ dmvaemz) usw. Deshalb ist es doch bestimmt sehr erfolgversprechend, das Programm aus Abbildung 1 mit Wörtern zu füttern, die aus einer Datenbank generiert werden, welche eine große Menge an Namen, Werken usw. enthält. Die Erstellung einer derartigen Datenbank ist in der heutigen Zeit dank world wide web und Co. kein Problem mehr.
Die meisten Nutzer machen es uns nicht ganz so leicht -- sie garnieren ihr Paßwort noch zusätzlich mit Sonderzeichen, manche schreiben Buchstaben groß oder verwenden an Stelle von Zahlwörtern bzw. Zahlwörtern sehr ähnlich klingenden Wörtern Ziffern (toofastforyou ↔ 2fast4you). Also werden wir unser Programm derart modifizieren, daß auf die potentiellen Paßwörter vor dem Verschlüsselungsvorgang Regeln angewendet werden, die das Wort etwas verändern.
Die Anzahl der potentiellen Paßwörter läßt sich somit auf ein akzteptables Maß reduzieren. Wenn man mit dieser Technik auch nicht alle Paßwörter entschlüsseln kann, so bleibt doch die Hoffnung, daß man vielleicht 10% der Paßwörter decodieren kann.
Ich habe auf sechs verschiedenen Netzen versucht, Paßwörter in Erfahrung zu bringen. Von ca. 1641 Paßwörtern konnte ich mit dem skizzierten Algorithmus 223 Paßwörter innerhalb eines Nachmittags auf einer Sparc 10 entschlüsseln. Verwendet habe ich hierzu ein frei verfügbares Programm namens Crack. Das Programm realisiert den oben beschriebenen Algorithmus. Es ist also nicht einmal nötig selber zu denken oder zu entwickeln.
Es stellt sich die Frage, warum ging dies so leicht?
Es bleibt noch anzumerken, daß ich natürlich kein Paßwort dazu verwendet habe, um widerrechtlich in ein fremdes System einzudringen. In Anbetracht der Problematik, die dieses Thema birgt, erschien mir es wichtig, darauf hinzuweisen und die Problematik durch Fakten zu untermauern.
Einleitung
Es gibt Werkzeuge mit denen troff -Dokumente für's Web aufbereitet werden können. Natürlich sollen die generierten Web-Seiten untereinander und mit der Welt verbunden sein, sowie Graphik, Tabellen und Mathematiksatz etc. enthalten können. Der zusätzliche Aufwand sollte minimal sein: zwei zusätzliche Makros sollten genügen. Wie dies geht, erfahren Sie in diesem Artikel.
Einige wenige Unverbesserliche, zu denen auch ich und einige meiner besten Freunde gehören, setzen ihre Texte immer noch mit den Mitgliedern der troff-Familie. Auch wir möchten unsere Texte, zumindest was die Optik anbelangt, in guter -- um nicht zu sagen in bester -- Qualität im Web publizieren. Die Anforderungen an die zu verwendenden Techniken sind hoch gelegt: Der Ausdruck und die Web-Seite sollen aus denselben Quellen erzeugt werden; die Web-Seiten sollen Querverweise und Graphik enthalten; jede Seite soll mit dem gleichen Rahmen versehen sein, damit die Navigation vereinheitlicht wird; eine Aufsplittung des Dokuments in kleine Einzelseiten soll an inhaltlich definierten Punkten automatisch erfolgen; ein Inhaltsverzeichnis und ähnlich nützliche Dinge sollten automatisch erzeugt werden; und ehrlich gesagt, möchte ich mich nicht so sehr mit HTML [1] beschäftigen.
Bevor ich zum ``wie'' komme, möchte ich Ihnen das Resultat zeigen. Eine Publikation im Web stelle ich mir wie folgt vor:
-- das Layout muß, soweit als möglich, einheitlich sein
-- die einzelnen Seiten sollten relativ kurz
sein und das Dokument sollte
nach inhaltlichen Gesichtspunkten
aufgeteilt sein. So sollte sich z.B. jedes Kapitel
und Unterkapitel auf einer eigenen Seite befinden.
Wird der vorliegende Artikel anstatt nach PostScript so nach HTML übersetzt, wie der Artikel beschreibt, erhält man als erste Web-Seite die in Abbildung 1 dargestellte Seite. Ein Klick auf bischof aktiviert ein mail-Tool; die Web-Seite unseres Fachbereichs, bzw. unserer Universität, erhält man durch ein Klicken auf die entsprechende Zeile.
Mit den vier Pfeilen links oben bzw. unten kann man sich durchs Dokument navigieren. Das I-Symbol, rechts von den Navigations-Pfeilen, führt zum Inhaltsverzeichnis. Mit einem Klick auf das Brief-Icon läßt man dem Autor eine Nachricht zukommen. Klickt man auf den Pfeil, welcher nach rechts zeigt, kommt man zur inhaltlich nächsten Seite. In unserem Fall ist das Abbildung 2. Das Inhaltsverzeichnis ist in Abbildung 3 dargestellt; es keine inhaltlich nächste oder vorherige Seite. Deshalb ist kein Navigations-Pfeil aktiv.
Der troff-Input für die erste Seite ist in Abbildung 4 dargestellt.
.NH 1
Von troff ins Web
.LP
.ce 9
.Hr -url mailto:bischof@informatik.uni-osnabrueck.de \
"Hans-Peter Bischof"
.Hr -url http://www.mathematik.Uni-Osnabrueck.DE/home_ge.html \
"Fachbereich Mathematik-Informatik"
.Hr -url http://www.informatik.uni-osnabrueck.de \
"Universit\*at Osnabr\*uck" .
.ce 0
.LP
.SH
Abstract
.LP
Einige wenige Unverbesserliche,
Abbildung 4: troff/unroff Input
Mit diesen Zeilen haben Sie alle zusätzlich Makros gesehen, die neben ein paar Programmen benötigt werden, um aus troff-Dokumenten Web-Seiten zu machen. Einfach, oder?
Lassen Sie mich, bevor wir in den nächsten Abschnitten zu den technischen Details kommen, erst die Randbedingungen, Ausgangssituation und Vorgehensweise beschreiben.
Ich schreibe meine Texte unter Unix und erzeuge PostSkript-Dateien mit den Werkzeugen der groff -Familie (groff(1), geqn(1), gtbl(1), gpic(1)) und lokal entwickelten Präprozessoren wie nsd [2]. In aller Regel wird bei der Übersetzung ein selbst entwickeltes Makropaket zusätzlich verwendet; Programmteile werden extrahiert und entsprechend aufbereitet -- Zeilennummern werden vorangestellt, \ durch \e ersetzt, etc -- und eingebunden. Gesteuert wird der Übersetzungsprozeß durch make(1). Mögliche Ziele sind hierbei:
1, 2, ... die einzelnen Kapitel all das komplette Manuskript spell Buchstabierkontrolle backup Anlegen einer Sicherungskopie clean Löschen von Zwischenresultaten nuke Löschen von allen generierten Dateien ...Es ist offensichtlich, daß die Pflege des makefiles aufwendig werden kann: Neue Projekte werden begonnen, Quellen innerhalb von existenten Projekten kommen hinzu, weitere Kapitel werden geschrieben, neue Quellen werden augelegt, etc. Weil die Nachführung bzw. der Neuaufbau von makefiles aon Hand nicht angenehm, sondern zeitraubend und langweilig ist, entwickelte ich ein makefile-Generierungsprogramm mk_gen, welches ein aktuelles makefile generiert.
Um dieses Skript möglichst ohne großen Aufwand erstellen und problemlos immer wieder verwenden zu können, war es hilfreich, eine gewissen Einheitlichkeit der Dokumente zu verlangen.
mk_gen funktioniert so gut, daß ich für die Produktion von PostSkript-Seiten in der Zwischenzeit keine makefiles mehr ``von Hand'' schreibe, sondern ausschließlich generieren lasse. Aus diesem Grunde sollte mk_gen so adaptiert werden, daß aus den troff-Quellen optional Web-Seiten generiert werden können.
Die Produktion von HTML-Seiten, Erstellen von Inhaltsverzeichnissen, Verbinden der Seiten, etc. zerfallen nach genauerer Analyse in zwei getrennte Problemkreise:
Das erste Problem kann man mit Werkzeugen lösen, welche sich im Netz finden. Grundsätzlich sind zwei verschiedene Wege gegangen worden:
troff2html ist ein perl-Skript, das ein troff-Dokument, falls es mit dem me-Makropaket geschrieben ist, nach HTML konvertieren kann. Folgende Funktionalität ist existent:
-- das me-Makropaket kann verwendet werden
-- die Ausgabe der Präprozessoren kann durch nroff
weiter übersetzt bzw. via GIF-Bild
inline eingebunden werden
-- alle ISO-8859-1 Sonderzeichen werden übersetzt
-- Inhaltsverzeichnis kann erzeugt werden
-- Navigationsleiste kann erzeugt werden
-- ein Aufsplitten des Dokuments ist konfigurierbar
-- eigene Makros können nur mit erheblichem Aufwand eingebaut werden
Das Resultat von troff2html ist nur dann befriedigend, wenn man keine in sich bzw. in die ``Welt'' verbundene Seiten generieren möchte. Die sehr komplizierte Adaption eigener Makros, Setzen von Registerwerten etc., schränkt den möglichen Einsatzbereich doch sehr ein. Ich fand troff2html für meine Anforderungen als nicht akzeptabel gefunden.
man2html ist ein perl-Skript, das Unix-Manual-Seiten nach HTML übersetzt und die Seiten untereinander auch verbindet. man2html akzeptiert als Eingabe mit nroff formatierte Manual-Seiten und generiert daraus eine HTML-Seite. Ein typischer Aufruf ist:
$ man echo | man2html > echo.html
Da man2html die Struktur der formatierten Seiten kennt, ist eine Umsetzung des Texts in HTML nicht weiter schwierig. Der generierte Text für den obigen Aufruf ist in Abbildung 5 dargestellt.
<HTML>
<BODY>
<PRE>
echo - display a line of text
</PRE>
<H2>SYNOPSIS</H2><PRE>
<STRONG>echo</STRONG> [<STRONG>-ne</STRONG>] [<EM>string</EM> ...]
<STRONG>echo</STRONG> {--help,--version}
Abbildung 5: man echo | man2html | sed 10q
Schwieriger stellt sich die Sache dar, wenn die Seiten untereinander verbinden werden sollen. In diesem Fall kann sich man2html nur darauf verlassen, daß sich für Verweise der Art cmd(I), die an beliebiger Stelle im vorformatierten Text auftauchen können, eine Seite im Dateisystem an der Stelle manI/cmd.1 befindet bzw. diese Seite bei Bedarf erzeugt werden kann. Die Perl-Spezifikation des Musters lautet:
/([\+_\.\w-]+)\((\d)(\w?)\)/).
Für die Manual-Pakete einzelner Hersteller kann der Teil des perl-Skripts, der die Crossreferenzen einfügt, problemlos modifiziert werden.
Für man2html gibt es auch eine CGI-Schnittstelle. Diese kann allerdings bei unsachgemäßer Installation und böshafter Nutzung zu sehr viel Ärger führen. Die Anfrage nach ls; rm -rf / wird letztlich das Kommando man ls; rm -rf / ausgeführt.
Als Produzenten für ``rohe Seiten'' zum Beispiel als Begleitmaterial einer Vorlesung, kann man2html problemlos eingesetzt werden.
Unroff bearbeitet ein Dokument, welches mit troff gesetzt werden kann, und übersetzt dies in ein anderes Format, z.B. SGML oder HTML. Die konkrete Ausprägung der Übersetzung wird durch benutzerdefinierte Regeln und Funktionen spezifiziert. Die Programmierbarkeit wird durch die Nutzung von elk, einer Scheme-basierten Sprache erreicht. Je nach Back-End kann grundsätzlich jede beliebiges Ausgabeformat erreicht werden.
Besonders interessant ist, daß unroff einen vollständigen troff-Interpreter enthält. Dies hat zur Konsequenz, daß auch Dokumente, die ein eigenes Makropaket verwenden, mit unroff umgewandelt werden können.
Die Dokumente können untereinander durch Verweise verbunden sein, ebenso können externe Verweise verwendet werden.
Die Produktion der Web-Seiten ist grob in drei Schritte unterteilt.
Werden die Dokumente mit unroff übersetzt, können zusätzlich zwei Makros benutzt werden, um die Hypertext-Verweise zu generieren.
Der Aufruf von unroff lautet zum Beispiel:
$ unroff -ms \ document=all \ split=2 \ hyper.scm \ lib/header c.01
c.01 wird mit dem ms-Makropaket gesetzt, wobei die Angabe von split=2 dafür sorgt, daß aus jedem Kapitel und aus jedem Unterkapitel erster Stufe eine eigene Seite wird, deren Dateiname mit all- beginnt. In hyper.scm sind die Hypertext-Anweisungen implementiert. lib/header enthält ein lokales Makropaket.
Wird c.01 mit troff gesetzt, lautet der Aufruf:
$ groff -tep -ms \ lib/header c.01
Unroff kann trotz aller Mühen nicht alles in eine Web-Seite verwandeln, was man mit troff und seinen Präprozessoren setzen kann. Tabellen setzt unroff tbl und nroff und setzt sie dann als Text ein. Komplizierte typographische Objekte wie Mathematik-Satz, Liniengraphik etc. werden aus dem Text extrahiert, mit eqn und troff gesetzt, und letztlich in ein gif-Format umgewandelt. Ein Beispiel zeigt Abbildungldung 6.
Will man in Tabellen komplizierte typographische Objekte einbinden stößt man an die Grenzen der Architektur von unroff.
Weiteren Präprozessoren wie grap oder nsp kann können dagegen problemlos verwendet werden. So gesehen fügt sich unroff in die troff-Architektur optimal ein.
Das gesammte Verfahren ist zweistufig, weil unroff keinen Überblick über die produzierten Web-Seiten hat.
Ein Setzen des Dokuments mit split=2 und document=all führt zu Dateinamen der Gestalt
all-1
all-1.1
all-1....
all-2
all-2.1
all-2....
Der Pfeil in den Navigationsleisten nach rechts bzw. links soll immer zur nächsten bzw. zur vorhergehenden Seite verweisen, falls diese existiert; falls nicht soll ein Link auf einen Verweis eingebaut werden, der anzeigt, daß hier die Welt zu Ende ist und der Pfeil ist durchgestrichen. Der Pfeil nach oben bzw. unten soll immer zur nächsten bzw. zur vorhergehenden Hauptkapitel verweisen, falls dieses existiert. Das nachfolgende Teil eines Shellskripts verbindet die Seiten korrekt.
...
304
305 doLink() # prefix j i
306 {
307 LEFT= `find_prev $1 $2 $3` # naechste Seite
308 RIGHT=`find_next $1 $2 $3` # vorhergehende Seite
309 UP= `find_up $1 $2` # vorhergehendes Kapitel
310 DOWN= `find_down $1 $2` # naechstes Kapitel
311 create_frame $4 $LEFT $RIGHT $UP $DOWN $PREFIX.html
312 }
313 j=1
314 i=0
315 while : # ueber alle Kapitel
316 do
317 if [ $i -eq 0 ]
318 then # Hauptkapitel
319 FILE=$PREFIX-$j.html
320 else # Unterkapitel
321 FILE=$PREFIX-$j.$i.html
322 fi
323
324 if [ -f $FILE ] # am Ende der Welt?
325 then
326 doLink $PREFIX $j $i $FILE
327 else
328 j=`expr $j \+ 1`
329 if [ ! -f $PREFIX-$j.html ]
330 then
331 break
332 fi
333 i=-1
334 fi
335
336 i=`expr $i \+ 1`
337
338 done
339
...
Unter Verwendung der vorgestellten Technik kann man mit unroff auch die Manualseiten in Web-Seiten umwandeln. Es wird ein zum Manual-Baum paralleler Baum aufgebaut, der anstelle von troff-Input HTML-Seiten enhält. Zusätzlich müssen nur zwei weitere Shellskripte eingesetzt werden, um die Navigation zu erleichtern. Eines setzt die Querverweise in HTML-Verweise um, das andere generiert ein Inhaltsverzeichnis für jeden Katalog, in dem sich HTML-Seiten befinden. Siehe Abbildung 7 und 8. Für jedes Problem wurde ein Skript entwickelt, wobei angemerkt werden muß, daß die Querverweise nur dann eingebaut werden konnten, wenn die Verweise in den Manualseiten systematisch verwendet wurden.
So werden in den Manuals zu Sun OS 4.1.3 bzw. Solaris 2.0 alle Verweise mit dem Makro BR gesetzt. Das Skript kann auf jede Systematik angepaßt werden. Werden die Manualseiten unsystematisch geschrieben, ist es nicht möglich, alle Querverweise in die HTML-Seiten aufzunehmen.
Todd Brunhoff (Tektronix) entwickelte im Zusammenhang mit dem Projekt Athena (MIT) eine Technik, mit der installationsunabhängig Makefiles beschrieben werden können. In einer installationsunabhängigen Imakefile-Datei wird der Zusammenhang Ziel-Quelle inklusive der zugehörigen Aktionen unter Verwendung von vordefinierten C-Makros und Konstanten definiert. In den installationsabhängigen template-Dateien werden diese C-Makros und Konstanten (CFLAGS, CC, ...) definiert. imake erzeugt dann, ausgehend von einer Imakefile-Datei, auf jeder Installation ein korrektes Makefile. In diesem Artikel wird imake aus X11 Release 5 beschrieben.
Generiert und installiert man Software unter Unix, dann hat man neben dem üblichen Geplänkel mit den Fehlern der Utilities das Problem, daß die Schnittmenge der Gemeinsamkeiten der verschiedenen Ziel-Plattformen gegen die leere Menge strebt. Es gibt umso weniger Gemeinsamkeiten, je mehr Fremdsoftware auf den Rechnern installiert ist. Exemplarisch seien einige Probleme aufgeführt:
Jeder, der Software portiert, muß seine Makefiles an die jeweilige Installation anpassen. Es wäre doch wesentlich arbeitssparender, wenn die in den Makefiles benötigte Information aus zentral gehaltenen, für die jeweilige Installation zugeschnittenen ``Datenbanken'' stammen würde. Im Zusammenhang mit der Entwicklung von X machten sich die Entwickler am MIT u.a. auch über die Portierungsmechanismen Gedanken. Folgende Prinzipien sollten bei der Entwicklung eines Werkzeugs berücksichtigt werden:
Als Lösung wird imake angeboten -- eine Koproduktion aus Konfigurationsdateien, C-Makros, make und dem C-Präprozessor cpp.
Abbildung 1 zeigt ein Imakefile für xcalc (von John H. Bradley, University of Pennsylvania),
$ cat -n Imakefile 1 XCOMM $XConsortium: Imakefile,v 1.8 91/08/15 12:19:56 rws Exp $ 2 #if defined(MacIIArchitecture) || defined(MotoR4Architecture) 3 IEEE_DEFS = -DIEEE 4 #endif 5 DEFINES = $(IEEE_DEFS) $(SIGNAL_DEFINES) 6 DEPLIBS = XawClientDepLibs 7 LOCAL_LIBRARIES = XawClientLibs 8 SYS_LIBRARIES = -lm 9 SRCS = actions.c math.c xcalc.c 10 OBJS = actions.o math.o xcalc.o 11 ComplexProgramTarget(xcalc) 12 InstallAppDefaults(XCalc)
Abbildung 1: ``Imakefile'' für ``xcalc''
Abbildung 2 zeigt einen Teil des entstehenden Makefiles.
$ imake $ cat Makefile ... 1 # $XConsortium: Imakefile,v 1.8 91/08/15 12:19:56 rws Exp $ 2 3 DEFINES = $(IEEE_DEFS) $(SIGNAL_DEFINES) 4 DEPLIBS = $(DEPXAWLIB) $(DEPXMULIB) $(DEPXTOOLLIB) $(DEPXLIB) 5 LOCAL_LIBRARIES = $(XAWLIB) $(XMULIB) $(XTOOLLIB) $(XLIB) 6 SYS_LIBRARIES = -lm 7 SRCS = actions.c math.c xcalc.c 8 OBJS = actions.o math.o xcalc.o 9 10 PROGRAM = xcalc 11 12 xcalc: $(OBJS) $(DEPLIBS) 13 $(RM) $@ 14 $(CC) -o $@ $(OBJS) $(LDOPTIONS) $(LOCAL_LIBRARIES)\ 15 $(LDLIBS) $(EXTRA_LOAD_FLAGS) 16 install:: xcalc 17 @if [ -d $(DESTDIR)$(BINDIR) ]; then set +x; \ 18 else (set -x; $(MKDIRHIER) $(DESTDIR)$(BINDIR)); fi 19 $(INSTALL) -c $(INSTPGMFLAGS) xcalc $(DESTDIR)$(BINDIR) 20 21 install.man:: xcalc.man 22 @if [ -d $(DESTDIR)$(MANDIR) ]; then set +x; \ 23 else (set -x; $(MKDIRHIER) $(DESTDIR)$(MANDIR)); fi 24 $(INSTALL) -c $(INSTMANFLAGS) xcalc.man \ 25 $(DESTDIR)$(MANDIR)/xcalc.$(MANSUFFIX) 26 install:: XCalc.ad 27 @if [ -d $(DESTDIR)$(XALPLOADDIR) ]; then set +x; \ 28 else (set -x; $(MKDIRHIER) $(DESTDIR)$(XALPLOADDIR)); fi 29 $(INSTALL) -c $(INSTALPFLAGS) XCalc.ad $(DESTDIR)$(XAPPLOADDIR)/XCalc ....
Abbildung 2: Teil des aus Abbildung 1 resultierenden ``Makefiles''
Betrachtet man die beiden Dateien etwas genauer, wird klar, wie die Makros ComplexProgramTarget (siehe auch Abbildung 6) und InstallAppDefaults aussehen müssen.
Durch den C-Makro ComplexProgramTarget (Abb. 1, Zeile 11) werden die Regeln generiert, mit denen man xcalc generieren (Abb. 2, Zeilen 12-15) und installieren (Abb. 2, Zeilen 16-19) und die Manualseiten (Abb. 2, Zeilen 21-25) installieren kann. In diesem C-Makro wird u.a. die Information der zuvor definierten Konstanten verwendet. Der C-Makro InstallAppDefaults generiert die Regeln, mit denen die zugehörige Ressourcedatei (Abb. 2, Zeilen 26-29) installiert werden kann.
imake
ist ein kleines, einfaches,
und dabei doch sehr nützliches Programm.
Unter Kontrolle von
imake
liest der C-Präprozessor die öffentlichen
Konfigurations- (*.cf),
Template- (*.tmpl) und Regeldateien (*.rules).
In diesen Dateien werden C- und make-Makros definiert.
Im
Imakefile
des Anwenders kann man diese
ersetzen bzw. ergänzen,
und man läßt sich die nötigen make-Regeln
durch Aufruf von C-Makros,
z.B.
ComplexProgramTarget
generieren.
Das Wissen über die konkreten Verhältnisse, die auf einer bestimmten Plattform herschen, ist in zentral verwalteten Dateien (Imake.tmpl, machine.cf , Lib.rules und site.def ) abgelegt. Je Projekt -- wie etwa X11 oder Motif -- wird in der Regel eine Template- und eine Regel-Datei gepflegt. Lokal entwickelte Dateien verwenden meistens existente Regel- oder Template-Dateien. Diese enthalten sehr viel undokumentierte Information. Das aus Sicht des Entwicklers entstehende Dilemma ist offensichtlich. In aller Regel läßt es sich nur durch das aufwendige Studium der entsprechende Konfigurationsdateien (ca. 3000 Zeilen) lösen.
Abbildung 3 zeigt den Aufbau von Imake.tmpl.
![[picture]](one_file-3.gif)
Abbildung 3: Aufbau von ``Imake.tmpl''
Imake.tmpl bildet den Rahmen, in den die weiteren Dateien via include eingebunden sind. In Imake.tmpl werden für fast alle benötigten Kommandos, Pfade und Flaggen symbolische Namen definiert. Von dieser generischen Plattform abweichende Werte müssen in site.def bzw. machine.cf (z.B. sun.cf) definiert werden. Die Auswahl der korrekten maschinenspezifischen Plattform geschieht durch cpp in Verbindung mit imake. In site.def werden alle aufgrund der lokalen Installation vom default-Wert abweichenden Variablen, z.B. ProjectRoot und UsrLibDir , definiert. In machine.cf werden die das Betriebssystem beschreibenden Variablen definiert. Die
#ifndef x # define x #endif
Technik garantiert, daß die Variablen nicht in den nachfolgenden Dateien überdefiniert werden. In aller Regel müssen site.def und machine.cf vom lokalen Systemadministrator ediert werden.
In Project.tmpl werden alle für das Projekt spezifischen Variablen festgelegt. Imake.rules enthält alle Definitionen der verwendbaren Makros. Imakefile beschreibt die Quellen und Ziele sowie deren Zusammenhang. Alles, was von cpp nicht bewertet werden kann, wird durchkopiert. Somit können an dieser Stelle auch ganz ``normale'' Makefile -Anweisungen stehen.
Die Funktionsweise von imake basiert im wesentlichen darauf, daß der C-Präprozessor ein maschinenabhängiges Symbol definiert hat, um Konditionalisierung der Art:
#ifdef sun
Sun-spezifische
Definition
#endif
zu ermöglichen. Beim Entwurf von imake konnte selbstverständlich nicht davon ausgegangen werden, daß jeder C-Präprozessor ein eindeutiges Symbol definiert. Aus diesem Grund wurde die Möglichkeit geschaffen, durch Änderung einer imake include -Datei (imakedep.h) den internen Aufruf des C-Präprozessors so zu gestalten, daß an ihn eine Option der Form -Duniq_symbol übergeben wird.
Im Vektor cpp_argv aus imakedep.h steht, welches Kommando (cpp oder cc) als Präprozessor verwendet und mit welchen Optionen das Kommando aufgerufen wird. Der Vektor wird mit der bekannten #ifdef ...-Technik statisch initialisiert. Sollten in diesem Bereich Probleme auftauchen, müssen die Quellen verändert werden. In diesem Fall sind die Punkte Step 1 und Step 5 in imakedep.h zu beachten.
An einem Beispiel wollen wir imake auf dem Weg durch das Labyrinth der Dateien auf einem Sun-Arbeitsplatzrechner verfolgen. Falls die Konfigurationsdateien nicht im default-Katalog liegen, wird imake der Pfad, der zu den Konfigurationsdateien führt, über die Environmentvariable IMAKEINCLUDE oder als Option auf der Kommandozeile angegeben. Abbildung 1 zeigt die Eingabe für imake. Im default-Fall sucht imake im aktuellen Katalog nach der Datei Imakefile und generiert eine Datei namens Makefile.
Imake.tmpl ist die erste Datei, die von imake gelesen wird. Als eine der ersten Zeilen findet sich dort: #define XCOMM # (siehe auch Abb. 1, Zeile 1). Im weiteren wird somit das Wort XCOMM als Kommentarbeginn betrachtet. Mit diesem Mechanismus wurde die Möglichkeit geschaffen, Kommentar besonders hervorzuheben. Falls lokale C-Präprozessoren an dieser Stelle scheitern sollten, hilft ein \ vor dem #. Mit der Phrase aus Abbildung 4 wird fixiert, in welcher Datei die plattformspezifische Information zu finden ist.
#ifdef sun # define MacroIncludeFile <sun.cf> # define MacroFile sun.cf # undef sun # define SunArchitecture #endif /* sun */
Abbildung 4: Bestimmung der maschinenspezifischen Beschreibung
Die nächste wesentliche Zeile in
Imake.tmpl
lautet:
#include MacroIncludeFile.
In sun.cf werden u.a. die Betriebssystemversion (OSMajorVersion und OSMinorVersion ) und verschiedene Flaggen gesetzt, welche die Generierung (XsunMonoServer) bzw. Installation (SetTtyGroup) beeinflussen. Die Regeln, nach denen Büchereien auf einer Sun-Architektur gebaut und installiert werden, werden in sunLib.rules definiert. Diese Datei wird via include in sun.cf eingebunden. Die nächsten wesentlichen Zeilen in Imake.tmpl definieren zwei C-Makros, mit denen zwei (Concat) bzw. drei (Concat3) Strings zusammengefügt werden können. Weil diese in den weiteren Dateien benutzt werden, findet die Definition an dieser, etwas unlogischen Stelle statt.
Nach dieser Definition
wird die für den lokalen Systemadministrator wichtigste Datei
mit
#include <site.def>
gelesen.
In dieser Datei wird all das definiert,
was die lokale Installation
von der
default -Installation
unterscheidet.
Bei uns finden sich dort die Definitionen aus Abbildung 5.
#ifdef sun # define MacroIncludeFile <sun.cf> # define MacroFile sun.cf # undef sun # define SunArchitecture #endif /* sun */
Abbildung 4: Bestimmung der maschinenspezifischen Beschreibung
#define UsrLibDir /usr/llib #define IncRoot /usr/linclude #define ManDirectoryRoot /usr/man/sun_manx #define BinDir /usr/lbin/X11 #define ManSuffix 1
Abbildung 5: Lokale Veränderungen in ``site.def''
Die nächsten 500 Zeilen in Imake.tmpl gießen die real vorhandene Plattform in eine imaginäre. Alle Kommandos wie
(#define CppCmd /lib/cpp),
Optionen, Pfadkomponenten, Pfade usw., die im weiteren benutzt werden, sind jetzt hinter symbolischen Namen verborgen.
Project.tmpl enthält alles X-Spezifische. Mit Konstanten wird gesteuert, ob ein Fontserver (BuildFontServer) gebaut wird, mit welcher Kennung die Manualseiten (LibManSuffix und ManSuffix) abgelegt werden und derlei Dinge mehr. sunLib.tmpl enthält alle projektspezifischen Informationen, die Büchereien betreffen. Die Versionsnummern der shared library (#define SharedXlibRev 4.10) werden dort ebenso fixiert wie die Pfade, die zu den X-Bibliotheken führen. Diese beiden Dateien werden in aller Regel nicht modifiziert. Soll ein neues Projekt mit imake verwaltet werden, muß meistens eine neue Projekt-Datei entwickelt werden. Die Kunst besteht dann darin, alle projektspezifischen Informationen in korrekter Abhängigkeit anzuordnen.
In Imake.rules werden ca. 120 C-Makros definiert, die zum Generieren und Installieren des Projekts, in diesem Fall X11 Release 5, verwendet werden. Abbildung 6 zeigt die Definition von ComplexProgramTarget.
#define ComplexProgramTarget(program) @@\
PROGRAM = program @@\
@@\
AllTarget(program) @@\
@@\
program: $(OBJS) $(DEPLIBS) @@\
RemoveTargetProgram($@) @@\
$(CC) -o $@ $(OBJS) $(LDOPTIONS) \
$(LOCAL_LIBRARIES) $(LDLIBS) $(EXTRA_LOAD_FLAGS) @@\
@@\
SaberProgramTarget(program,$(SRCS),$(OBJS), \
$(LOCAL_LIBRARIES),NullParameter) @@\
@@\
InstallProgram(program,$(BINDIR)) @@\
InstallManPage(program,$(MANDIR))
Abbildung 6: Definition des C-Makros ``ComplexProgramTarget''
Dieser Makro verwendet die zuvor definierten Makros und Konstanten.
Imake sammelt alle benötigten Dateien auf, die defines werden eingesetzt, die Makros bewertet und fertig ist das Makefile. So weit, so gut. Aber an sich sollten für imake zum Generieren und Installieren der Software dieselben Konfigurationsdateien wie beim Entwickeln mit der später installierten Software verwendet werden. Der Unterschied im Makefile , der zwischen Generierung der Software innerhalb des Quellbaums und der Benutzung der installierten Software liegt, ist in aller Regel nur in den Pfaden zu sehen, die zu den ausführbaren Programmen, den Bibliotheken und include -Dateien führen. Ein Beispiel: der Pfad, der zu einer Bibliothek führt, kann folgendes Aussehen haben: bei Generierung eines Objekts im Quellbaum ../../lib/libX11.a und bei der Generierung einer Applikation nach der Installation /usr/llib/X11/libX11.a. Trotzdem soll im Makefile in beiden Fällen jeweils derselbe symbolische Name benutzt werden können. Also müssen die entsprechenden Zuweisungen konditionalisiert werden, abhängig von der jeweiligen Verwendung. Wie der Pfad dann zusammengebaut werden muß, zeigt Abbildung 7.
/*
* _UseCat - combination of _Use and Concat.
* exists to avoid problems with some preprocessors
*/
#ifndef _UseCat
#if __STDC__ && !defined(UnixCpp)
#ifdef UseInstalled
#define _UseCat(a,b,c) a##c
#else
#define _UseCat(a,b,c) b##c
#endif
#else
#ifdef UseInstalled
#define _UseCat(a,b,c) a/**/c
#else
#define _UseCat(a,b,c) b/**/c
#endif
#endif
#endif
USRLIBDIR = /usr/llib/X11
TOOLKITSRC = ../../lib
XLIB = _UseCat($(USRLIBDIR),$(TOOLKITSRC),/libX11.a)
Abbildung 7: Konditionalisierte Zuweisung
Ein weiteres nützliches Werkzeug ist makedepend. Dieses, auch von Todd Brunhoff entwickelte Kommando, untersucht beliebige Dateien auf include-Anweisungen, generiert die daraus folgenden make-Regeln und fügt diese am Schluß zu dem Makefile hinzu. Es werden alle Konditionalisierungsmechanismen gemäß den Direktiven des C-Präprozessors behandelt. Abbildung 8 zeigt eine für ein Makefile typische Regel.
depend: $(SRC) makedepend -- $(CFLAGS) -- $(SRCS)
Abbildung 8: typische Regel eines Makefiles
Abbildung 9 die Ausgabe von % makedepend imake.c.
depend: $(SRC) makedepend -- $(CFLAGS) -- $(SRCS)
Abbildung 8: typische Regel eines Makefiles
# # ------------------------------------------------------------------------- # # dependencies generated by makedepend # DO NOT DELETE imake.o: /usr/include/stdio.h /usr/include/stddef.h /usr/include/stdarg.h imake.o: /usr/include/ctype.h .././X11/Xosdefs.h /usr/include/sys/types.h imake.o: /usr/include/fcntl.h /usr/include/signal.h /usr/include/sys/signal.h imake.o: /usr/include/sys/stat.h /usr/include/sys/wait.h imake.o: /usr/include/stdlib.h /usr/include/errno.h /usr/include/sys/errno.h imake.o: imakemdep.h # DO NOT DELETE THIS LINE -- make depend depends on it.
Abbildung 9: Resultat von ``makedepend imake.c''
Daß imake ein sehr gut funktionierendes Werkzeug ist, zeigt sich, wenn man X und Motif auf verschiedenen, nicht vorgesehenen Plattformen generiert und installiert. Man ist erstaunt, wie leicht es geht. Auch die Erweiterung der Konfigurationsdateien, um eigene Projekte in das System mit einbinden zu können, ist nicht schwierig. Ab und an fragt man sich allerdings, ob nicht mit Kanonen auf Spatzen geschossen wird, denn die für die Sun-Architektur benötigten Konfigurationsdateien umfassen zusammen ca. 3000 Zeilen. Um eine gezielte Änderung erreichen zu können, muß man gelegentlich schon etwas genauer hinsehen. Trotzdem, der Einsatz von imake und makedepend hat sich bei uns vielfach ausbezahlt. In diesem Fall gilt bestimmt nicht: ``Was nichts kostet, taugt nichts''.
J. Fulton, ``Configuration Management in the X Window System'', MIT, Dokumentation zu X11 Rev. 5.
S. Feldman, ``make -- A Program for Maintaining Computer Programs'', Software -- Practice and Experience, April 79.
1. alle zur Verfügung stehenden Ressourcen auf alle Beteiligten
gerecht verteilen
2. Arbeit erledigen
3. Daten halten
4. einen Netzanschluß bereitstellen
5. Kommunikationswege erschließen (world wide web)
6. Datenschutz gewährleisten
7. auftauchende Funktionsfehler erkennen.
Siehe auch: http://www.cs.arizona.edu/people/bridges/oses.html
Beispiele
----------------------------------------------------------------------------
CPU 80[345]86, 68[24]0, Sparc-Prozessor (Risc Architektur)
davon eine oder viele
Hauptspeicher (ca. Zahlen, abhängig vom genauen
Verwendungszweck)
1 MB für DOS
4 MB für Linux/Unix
8 MB für Plan 9
16 MB für Windows 95, Linux/Unix & X
32 MB für Windows 95
32 MB ist die untere Grenze für Unix/Workstations
64 MB ist normal für Unix/Workstations
128 MB ist wünschenswert für Unix/Workstations
512 MB ist für Server angesagt
Festplatten 1GB im PC-Bereich
4GB im WS-Bereich
Mehrere 100GB im Server-Bereich (Disk-Arrays)
Anbindung Ethernet: 10 MBit/Sekunde
ATM: 100 MBit/Sekunde
Token Ring
Bandgerät DAT-Laufwerke
Exabyte-Laufwerke (10GB)
Streamer-Laufwerke (mehrere 100MB)
Bildschirm 17 Zoll, Farbe, 100 DPI
Tastatur
Maus 2 oder 3 Knopf-Maus,
Trackball & AddOn-Tasten am Laptop
CDRom-Laufwerk
Disketten-Laufwerk
Soundkarte
![[picture]](one_file-4.gif)
+------------------------------------------------------------+ |A(u): Die Benutzerschnittstelle zum Rechner. | +------------------------------------------------------------+ |... verschiedene Schichten Anwendungssoftware | +------------------------------------------------------------+ |A(s): Die Schnittstelle zum Betriebssystem (Systemaufrufe). | +------------------------------------------------------------+ |A(h): Die Software/Hardware Schnittstelle. | +------------------------------------------------------------+ |... Hardware. | +------------------------------------------------------------+
1. Erzeugen 2. Anhalten (aktiv, passiv) 3. Reaktivieren (aktiv, passiv) 4. Terminieren (aktiv, passiv) 5. Kommunikation 6. Verteilung der Rechenzeit 7. Benutzeridentifikation 8. Rechte
1. Dateisystem als Baum 2. Pfade zu Dateien 3. Zugriff, u.U. exklusiv, auf Dateien 4. Zugriffsrechte
Systemaufrufe sind die Schnittstelle zwischen Betriebssystem und Benutzerprogramm. Die Gesamtmenge alle Systemaufrufe wird als application program interface, API, bezeichnet.
1. Swapping 2. Virtueller Speicher 3. Seitenaustauschalgorithmen
1. Eigenschaften von I/O-Hardware 2. Eigenschaften von I/O-Software 3. Festplatten 4. Uhren 5. Terminals
![[picture]](one_file-5.gif)
+---+---------------------------------------+ |5. | Operateur | +---+---------------------------------------+ |4. | Benutzerprogramme | +---+---------------------------------------+ |3. | Ein-/Ausgabeverwaltung | +---+---------------------------------------+ |2. | Operateur und Prozeßkommunikation | +---+---------------------------------------+ |1. | Speicher- und Trommelverwaltung | +---+---------------------------------------+ |0. | Prozeßvergabe und Multiprogrammierung | +---+---------------------------------------+Die Struktur des THE-Betriebssystems (E. W. Dijkstra, 1968)
![[picture]](one_file-6.gif)
A ----- ----- B ----- ----- C ----- ----- D ----- ----- E ----- ----
Wie entsteht eigentlich der erste Prozeß?
· rechnend · rechenbereit · blockiert
![[picture]](one_file-7.gif)
1. Prozeß wird blockiert
2. Scheduler wählt einen anderen Prozeß
aus der Menge der rechenbereiten
Prozesse.
3. Dieser Prozeß rechned.
Einfügen ausgelöst vom Parent-Prozeß
Entfernen ausgelöst vom Parent-Prozeß
doch was passiert, wenn kein
Parent-Prozeß mehr da ist?
Fairneß: Jeder Prozeß erhält einen gerechten An
teil der Prozessorzeit.
Effizienz: Der Prozessor ist immer optimal (voll
ständig) ausgelastet.
Antwortzeiten: Die Antwortzeit für interaktiv arbei
tende Programme wird minimiert.
Verweilzeit: Die Wartezeit auf die Ausgabe von Sta
pelaufträgen wird minimiert.
Durchsatz: Die Anzahl der Aufträge, die in einem
bestimmten Zeitintervall bearbeitet
werden können, wird maximiert.
Es stellen sich noch folgende Fragen:
![[picture]](one_file-8.gif)
![[picture]](one_file-9.gif)
1. Der Modus wechselt vom Benutzer- in den Kernel-Mode
2. Der Benutzer-Prozeß wird ein einen Kernel-Prozeß umgewandelt
3. Der Prozeß erhält spezielle Privilegien
a.) die Möglichkeit, Kernel-Speicherseiten zu modifizieren
b.) die Möglichkeit, die Priorität zu modifizieren
1. Setzen der Parameter für den Systemaufruf 2. Provozierung des Softwareinterrupts 3. Aufruf der Systemfunktion im Kern 4. Holen der Argumente 5. Abbarbeitung der Systemfunktion 6. Liefern des Resultats
1. Der Programmzähler and andere Information wird durch die Hardware
auf den Stack gelegt.
2. Die Hardware lädt den neuen Programmzähler aus
dem Unterbrechungsvektor.
3. Eine Assembler-Routine rettet die Registerinhalte.
4. Eine Assembler-Routine bereitet den neuen Stack vor.
5. Der Prozeß wird als rechenbereit markiert.
6. Der Scheduler bestimmt den Prozeß,
der als nächster ausgeführt werden soll.
7. Der Prozeß wird ausgeführt.
Dies ist eine kurzen Einführung in awk.
Die Sprache wird an Hand von kleinen Beispielen eingeführt.
Ein sehr gute Beschreibung findet sich in:
Aho/Kernighan/Weinberge, The AWK Programming Language, ISBN: 0-201-07981-X.
Der Aufruf von awk
gawk [ POSIX or GNU style options ] -f program-file [ -- ]
gawk [ POSIX or GNU style options ] [ -- ] program-text file
1 #
2 # numeriert die Zeilen einer Datei durch.
3
4 { printf "%4d: %s\n", NR, $0 }
1 #!/bin/sh
2 # sucht Nutzer ohne Passwort
3 # ypcat passwd | sed 2q
4 # operator:* noway *:5:5::/bin:
5 # odstumpe::26:220:Dieter Stumpe:/home/oop/odstumpe:...
6
7 ypcat passwd | awk '
8 /::/ { print $0 }
9 '
1 #!/bin/sh
2 # sucht Nutzer ohne Passwort
3 #
4 # ypcat passwd | sed 2q
5 # operator:* noway *:5:5::/bin:
6 # odstumpe::256:220:Dieter Stumpe:/home/oop/odstumpe:...
7
8 ypcat passwd | awk -F: '
9 $2 == "" { print $1, $5 }
10 '
1 #!/bin/sh
2 # sucht Nutzer ohne Passwort
3 # + BEGIN END
4 #
5 # ypcat passwd | sed 2q
6 # operator:* noway *:5:5::/bin:
7
8 ypcat passwd | awk -F: '
9 BEGIN { count = 0 }
10
11 $2 == "" { print $1, $5;
12 count ++ }
13
14 END { print "Es wurden ", count, "gefunden."
15 }
16
17 '
1 #!/bin/sh
2 # assoziative Felder
3 #
4
5 cat << EOF | awk '
6 { if ( names[$1] != "" )
7 names[$1] ++;
8 else
9 names[$1] = 1;
10 print $1
11
12 if ( names["aaa"] != "" )
13 names["aaa"] = 1
14 }
15 END { for ( i in names )
16 print i, ":", names[i]
17 }
18
19 '
20 one
21 two
22 three
23 four
24 two
25 EOF
1 #!/bin/sh
2 # assoziative Felder
3 #
4
5 cat << EOF | gawk '
6 { if ( $1 in names )
7 names[$1] ++;
8 else
9 names[$1] = 1;
10 print $1
11
12 if ( "aaa" in names )
13 names["aaa"] = 1
14 }
15 END { for ( i in names )
16 print i, ":", names[i]
17 }
18
19 '
20 one
21 two
22 three
23 four
24 two
25 EOF
1 #!/bin/sh
2 # Das erste und letzte Wort einer Zeile
3 #
4
5 cat << EOF | gawk '
6 { print NF, $0 ":" ,$1, $NF }
7
8 '
9 one
10 two TWO
11 three THREE
12 one
13
14 EOF
1 #!/bin/sh
2 # Number == String
3 #
4
5 gawk '
6 BEGIN { number = 99;
7 string = "099";
8 printf "string = %s, number = %s\n",
9 string, number ;
10 if ( string == number )
11 print "( string == number )";
12 else
13 print "( string !== number )";
14 if ( 0 + string == number )
15 print "( 0 + string = number )";
16 if ( string == "0" number )
17 print "( string = 0number )";
18
19 print string + number
20 }
21
22 '
1 #!/bin/sh
2 # String enthaelt pattern
3 # assoziative Felder
4 #
5
6 cat << EOF | gawk '
7 { if ( $1 ~ /[Bb]+ananen/ )
8 print $2, "moegen", $1
9 }
10 '
11 ananen Affen
12 Bbananen Affen
13 Bananen Affen
14 bananen affen
15 EOF
1 #!/bin/sh
2 # Setzen des Fieldseperators
3 #
4
5 cat << EOF | gawk -F'[.,% $PID F`;!?]' '
6 { for ( i = 1; i <= NF; i++ )
7 print $i
8 }
9 '
10 Ein Satz hat ein , und einen . Ende
11 EOF
Kommunikation zwischen sh und awk I:
1 #!/bin/sh
2 # Kommunikation zwischen sh und awk.
3 # 1. Shellvariable --> awk
4 # operator:* noway *:5:5::/bin:
5 # odstumpe:vQ:26:220:Dieter Stumpe:/home/odstumpe:...
6 # ypcat passwd | sed 2q
7
8 GID=11
9
10 echo $GID
11 ypcat passwd | awk -F: '
12 BEGIN { print "GID =", '"$GID"' }
13 $4 == '"$GID"' { print $1, $5 }
14 ' | more
Kommunikation zwischen sh und awk II:
1 #!/bin/sh
2 # Kommunikation zwischen sh und awk.
3 # 2. awk --> shell
4 # ypcat group | fgrep inform
5 # inform:*:11:
6 # eval GID=333
7 # echo "gid = $GID"
8
9 eval `ypcat group | awk -F: '
10 $1 == "inform" { print "GID=" $3 }
11 '`
12
13 echo "gid = $GID"
Kommunikation zwischen sh und awk III:
1 #!/bin/sh
2 # Kommunikation zwischen sh und awk.
3 # 2. awk <--> shell
4 # ypcat group | fgrep inform
5 # inform:*:11:
6 # eval GID=333
7 # echo "gid = $GID"
8
9 . shell_lib.a
10
11 case $#
12 in 0) fatal "`basename $0`: `basename $0` groupname"
13 esac
14
15 echo "ypcat group | grep -s $1"
16 ypcat group | grep "^$1:" > /dev/null
17
18 case $?
19 in 0) eval `ypcat group | awk -F: '
20 $1 == "'"$1"'" { print "GID=" $3 }
21 '`
22 ;; *) fatal "`basename $0`: Unknown group $1"
23 esac
24
25
26 echo "\$1 = $1, gid = $GID"
1 #!/bin/sh
2 # a) getline
3 # getline var
4 # getline < file
5 # getline var < file
6 # cmd | getline
7 # cmd | getline var
8 #
9
10 cat << EOF | gawk '
11 BEGIN { do
12 print ;
13 while ( ( getline > 0 ) && ( $1 !~ /wo/ ))
14 }
15 #BEGIN { while ( ( getline > 0 ) && ( $1 !~ /wo/ ))
16 # print ;
17 # }
18 #BEGIN { for ( ; ( getline > 0 ) ; ) {
19 # print "copy ", $0 ;
20 # if ( $1 ~ /wo/ )
21 # break
22 # }
23 # }
24 { print "----", $1, $2 }
25
26 '
27 zero 0000 00 000 0 0 0 00 copy
28 one AAA AAAA AAAA AAAA copy
29 two BBB BBB BBB BB BBB copy
30 three CC CC CCC CCC CCC CCC
31 four DDD DD DDD DDD DDD DDDD
32 two EEE EEE EEE EEE EEE
33 EOF
1 #!/bin/sh
2 # getline
3 # getline var
4 # b) getline < file
5 # getline var < file
6 # cmd | getline
7 # cmd | getline var
8 #
9
10 gawk '
11 BEGIN { i = 0;
12 while ( ( getline < "file" > 0 ) &&
13 ( i++ <= 2 ) ) {
14 print "====", $0;
15 }
16 }
17 END { print "END"
18 while ( getline < "file" > 0 )
19 print "----", $0;
20 } ' $0 # Inputfile ist notwendig
1 #!/bin/sh
2 # getline
3 # getline var
4 # getline < file Vorsicht
5 # getline var < file
6 # c) cmd | getline
7 # cmd | getline var
8 #
9
10 gawk '
11 BEGIN { n = 0
12 while ("who" | getline > 0 )
13 n++
14
15 print "# user = ", n
16 } '
1 #!/bin/sh
2 # output into files
3 #
4
5 gawk '
6 BEGIN { print "BIG" > "big"
7 print "BIG" >> "big"
8 close( "big")
9 system("cat big")
10 } '
1 #!/bin/sh
2 # Ausgabe auf stderr
3 #
4
5 gawk '
6 BEGIN { print "Message 1: cat 1>&2" | "cat 1>&2"
7 print "system(\"echo ^\"Message: :\"^ 1>&2 \")"
8 system("echo '"Message 2: "' 1>&2 ")
9 print "Message: > /dev/tty" > "/dev/tty"
10 } '
1 #!/bin/sh
2 # output into pipe print | cmd
3 #
4
5 ypcat passwd | gawk -F: '
6 BEGIN { counter = 0
7 }
8 $4 == 11 { print counter
9 if ( counter++ < 5 )
10 print $1 | "sort -r"
11 else
12 exit # go immediately to
13 # the END pattern
14 }
15 END { print "END"
16 close("sort -r")
17 }
18 '
1 #!/bin/sh
2 # arguments
3 #
4
5 gawk '
6 BEGIN { print "ARGC = ", ARGC
7 for ( i = 0; i < ARGC; i ++ )
8 print "ARGV[" i "] = ", ARGV[i]
9 }
10 { print "---", $0, "-----" }
11
12 ' "$@"
1 #!/bin/sh
2 # arguments
3 #
4
5 gawk '
6 BEGIN { print "ARGC = ", ARGC
7 for ( i = 0; i < ARGC; i ++ ) {
8 print "ARGV[" i "] = ", ARGV[i]
9 ARGV[i] = ""
10 }
11 }
12 { print "---", $0, "-----" }
13
14 ' "$@"
1 #!/bin/sh
2 # arguments
3 #
4
5 gawk '
6 BEGIN { print "ARGC = ", ARGC
7 for ( i = 0; i < ARGC; i ++ ) {
8 if ( ARGV[i] ~ /^-/ ) {
9 print "Flag: ", ARGV[i]
10 if ( ARGV[i] ~ /^-x$/ ) {
11 print "-x"
12 ARGV[i] = ""
13 } else if ( ARGV[i] ~ /^-f$/ ) {
14 print "-f"
15 print "file: ", ARGV[i+1]
16 ARGV[i] = ""
17 ARGV[i+1] = ""
18 }
19 } else
20 if ( ARGV[i] != "" )
21 print "Inputfile: ", ARGV[i]
22
23 }
24
25 }
26 { print "---", $0, "-----" }
27
28 ' "$@"
1 #!/bin/sh
2 # arguments
3 #
4
5 gawk '
6 BEGIN { print "ARGC = ", ARGC
7 i = 1
8 while ( ( i < ARGC ) && ( ARGV[i] != "--" ) ) {
9 print i ":", ARGV[i]
10 if ( ARGV[i] ~ /^-x$/ ) {
11 print "-x"
12 ARGV[i] = ""
13 } else if ( ARGV[i] ~ /^-f$/ ) {
14 print "-f"
15 if ( ( i < ARGC - 1 ) &&
16 ( ARGV[i+1] != "--" ) ) {
17 print "file: ", ARGV[i+1]
18 ARGV[i] = ""
19 ARGV[++i] = ""
20 } else {
21 print "Missing Argument for -f."
22 exit
23 }
24 }
25 i++
26 }
27 if ( ARGV[i] == "--" )
28 ARGV[i] = ""
29 }
30 { print "---", $0, "-----" }
31
32 ' "$@"
1 #!/bin/sh
2 # functions
3 #
4
5 gawk '
6 # call by value
7 function max(first, second, m) {
8 m = first > second ? first : second
9 first = 0
10 second = 0
11 return m
12 }
13
14 BEGIN { f = 2;
15 s = 3;
16 print "max(" f "," s ") = " max(f,second)
17 print "f = ", f
18 print "s = ", s
19 }
20 '
1 #!/bin/sh
2 # functions
3 #
4
5 gawk '
6 # call by reference
7 function max(field, m) {
8 m = field[0] > field[1] ? field[0] : field[1]
9 field[0] = 0
10 field[1] = 0
11 return m
12 }
13
14 BEGIN { f[0] = 2;
15 f[1] = 3;
16 print "max(" f[0] "," f[1] ") = " max(f)
17 print "f[0] = ", f[0]
18 print "f[1] = ", f[1]
19 }
20 '
1 #!/bin/sh
2 # pattern
3 # ^ begin of string
4 # . any character
5 # [c1c2] any character in c1c2
6 # [^c1c2] any character not in c1c2
7 # [c1-c2] any character in range beginning with c1
8 # ending with c2
9 # [^c1-c2] any character not in range beginning with c1
10 # ending with c2
11 # r1|r2 any string x matched by r1 or r2
12 # (r1) any string matched byt r1
13 # (r1)(r2) any string xy where r matches r1 and
14 # y matches r2
15 # (r1)* zero or more
16 # (r1)+ one or more
17 # (r1)? one or zero
18 #
19
20 cat << EOF | gawk '
21 /AFFE|affe/ { print "AFFE oder affe: ", $0 }
22 /M([ae]i|ay)er/ { print "M?ier: ", $0 }
23 /^[^aeM]/ { print "[^aeM]: ", $0 }
24 /^[0-9]+\.?[0-9]+/ { print "^[0-9]+\\.?[0-9]+:", $0 }
25 /^[0-9]+\.?[0-9]+$/ { print "^[0-9]+\\.?[0-9]+$:", $0 }
26 /^[0-9]+\.?[0-9]+[ ]*(e[+-]?[ ]*[0-9]+)?$/ \
27 { print "^[0-9]+\\.?[0-9]+(e[+-]?[0-9]+)?$:",
28 $0 }
29 '
30 affe
31 AFfe
32 AFFE
33 Maier
34 Meier
35 Mayer
36 Maiyer
37 100,20
38 100.20
39 100.20 e10
40 100.20 e-10
41 100.20 e+10
42 EOF
|
|
|
Last modified 03/July/97