20.8.3 | Parsen des Dokuments
|
Der nächste Schritt ist die Prüfung eines Dokuments mit einem speziellen Programm, dem so genannten XML-Parser. XML-Parser sind mittlerweile von zahlreichen Anbietern verfügbar. Der im J2SDK 1.4 standardmäßig enthaltene Parser stammt ursprünglich von Sun und wurde später unter dem Namen Crimson vom Apache-Projekt weiterentwickelt. Ebenfalls sehr verbreitet ist Xerces, der ebenfalls vom Apache-Projekt stammt und langfristig der Nachfolgekandidat für Crimson ist.
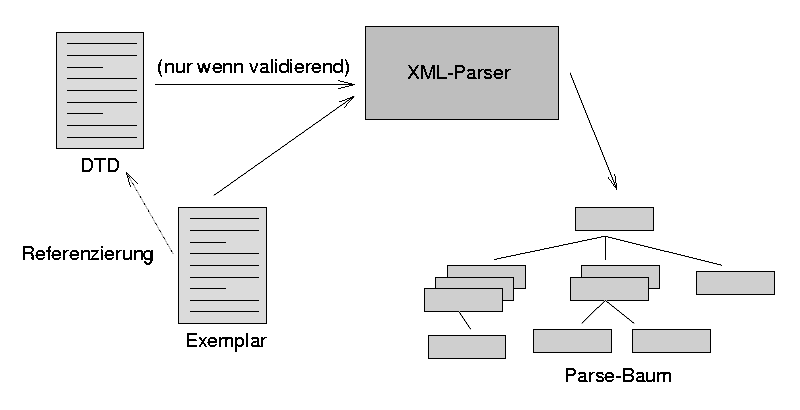
Bei den XML-Parsern unterscheidet man zwischen validierenden und nicht validierenden Parsern. Validierende Parser prüfen das Dokument auf Übereinstimmung mit seiner DTD. Hierzu laden sie neben dem Exemplar auch die DTD. Verstößt das Dokument gegen die Struktur (z.B. falsche Reihenfolge oder falsche Schachtelung von Elementen, Verwendung unbekannter Elemente oder Attribute) oder weist es Syntax-Fehler auf (z. B. fehlende End-Tags oder Anführungsstriche bei Attributen) liefert der Parser entsprechende Fehlermeldungen. In diesem Fall muss das Exemplar geändert werden. Crimson und Xerces sind validierende Parser.
Nicht validierende Parser können viel leichtgewichtiger realisiert werden als validierende und benötigen entsprechend weniger Zeit zum Aufbau des Parse-Baums. Ein Beispiel für einen nicht validierenden XML-Parser, der in Java implementiert ist, ist James Clarks XP.
Abbildung 20.9: Parsen eines XML-Dokuments
 |
Nicht validierende Parser dagegen prüfen das Dokument nicht auf Übereinstimmung mit der DTD, sondern nur auf syntaktische Korrektheit und auf die Einhaltung bestimmter Konventionen. Im XML-Standard wird hierfür der Begriff wohlgeformt (»well formed«) definiert. Bedingungen für die Wohlgeformtheit eines Dokuments sind unter anderem:
- Es gibt nur ein Wurzelelement, das alle anderen Elemente enthält.
- Alle Elemente im Dokument sind korrekt geschachtelt (keine »Überlappungen«)
- Alle Elemente müssen mit einem End-Tag geschlossen sein.
Wohlgeformte XML-Dokumente können eine DTD-Deklaration haben, müssen es aber nicht. Wenn sie eine haben, wird die DTD von nicht validierenden Parsern ignoriert.
Bei der Analyse baut der Parser einen Parse-Baum auf, dessen Knoten
die Bestandteile des Dokuments repräsentieren.
Entsprechend den verschiedenen Teilen, aus denen ein XML-Dokument besteht, gibt
es verschiedene Knotentypen (für die DTD, Elemente, Attribute,
Entities usw.).
Ein einzelner Knoten kann z. B. ein Vorkommen eines in der DTD
definierten Strukturelements (Kapitel, Absatz, Aufzählung etc.)
repräsentieren oder auch einen Unicode-String enthalten (z. B. den Titel
eines Kapitels).
Nach einem erfolgreichen Parse-Vorgang kann der Parse-Baum der XML-Applikation übergeben und dort weiterverarbeitet werden.
Copyright © 2002 dpunkt.Verlag, Heidelberg. Alle Rechte vorbehalten.