Der Zugriff auf einen Parse-Baum mit DOM soll zunächst anhand eines Inhaltsverzeichnisses für ein Buch demonstriert werden. Ein Buch bestehe aus Kapiteln, deren Titel ausgegeben werden sollen:
<BOOK>
<CHAPTER>
<TITLE>XML</TITLE>
...
</CHAPTER>
...
</BOOK>
Abbildung 20.13 zeigt den Parse-Baum dieses Dokuments.
Abbildung 20.13: Ausschnitt aus dem Parse-Baum
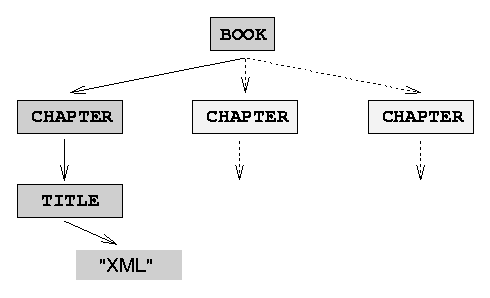 |
Bei der Traversierung ist zu beachten, dass Textdaten, in diesem Fall der Text des Titels, in einem eigenen Knoten abgelegt sind. Deswegen muss auf den TITLE-Knoten (der ja ein Element-Knoten ist) ein getFirstChild() angewendet werden, um an den Text-Knoten mit dem eigentlichen Titel heranzukommen.
Zunächst wird ein Exemplar eines Parsers erzeugt, der einen DOM-Baum aufbaut. Vom Prinzip erfolgt dies genauso wie bei SAX, nur dass in diesem Fall ein Exemplar der DocumentBuilderFactory zum Einsatz kommt, um einen DocumentBuilder zu erzeugen. Wie auch für SAX sind diese Klassen im Paket javax.xml.parsers definiert.
DocumentBuilderFactory factory;
DocumentBuilder builder;
// Abruf eines Factory-Exemplars
factory = DocumentBuilderFactory.newInstance();
// Erzeugung des Parsers über diese Factory
builder = factory.newDocumentBuilder();
Nach dem Parser-Durchlauf erfolgt eine Iteration über den Baum, um die TITLE-Elementknoten zu finden.
Document doc;
TreeWalker tw;
// DOM-Baum erzeugen
doc = builder.parse(new File(args[0]));
// TreeWalker erzeugen (funktioniert nur bei
// entsprechenden Implementierungen)
tw = ((DocumentTraversal)doc).
createTreeWalker(doc, NodeFilter.SHOW_ELEMENT, null, false);
Anstatt eine Iteration von Hand zu programmieren, wurde bei diesem Beispiel auf die Interfaces DocumentTraversal und TreeWalker aus dem Paket org.w3c.dom zurückgegriffen. Dieses gehört zwar nicht zum Standardumfang von J2SDK 1.4, wird aber von Xerces implementiert. Der im J2SDK 1.4 enthaltene Parser enthält keine Implementierung für das traversal-Paket, so dass für das gezeigte Beispiel ein anderer Parser wie Xerces eingesetzt werden muss. Bereits bei diesem einfachen Beispiel zeigt sich also, dass es sich oft anbietet, die Standardimplementierung zu ersetzen.
Die Iteration selbst erfolgt in einer while-Schleife, die die Methode nextNode() von TreeWalker solange abruft, bis sie null liefert, was das Ende des Dokuments signalisiert. Das Interface Node repräsentiert einen allgemeinen Knoten im Baum.
In der Schleife wird geprüft, ob es sich um ein CHAPTER-Element handelt. Falls ja, wird der Text im untergeordneten Textknoten ausgegeben. Hierzu wird ein Cast in das DOM-Interface Text vorgenommen, um anschließend mit der Methode getData() den Text auszulesen.
Node currentNode;
Text textNode;
// Über den Baum iterieren
while ((currentNode = tw.nextNode()) != null) {
// Bei TITLE-Elementen den Text ausgeben
if (currentNode.getNodeName().equals("TITLE")) {
// Der gesuchte Text steht im untergeordneten Textknoten
textNode = (Text)currentNode.getFirstChild();
System.out.println(textNode.getData());
}
}
Das nächste Beispiel zeigt, wie bestimmte Elementknoten auch ohne die Klasse im traversal-Paket gesucht werden können. Hierzu wird die Methode getElementsByTagName() verwendet, die in Document und Element verfügbar ist. Diese ist in der Handhabung zwar einfacher als eine Iteration über den Baum, allerdings ist die Suche dahingehend beschränkt, dass nur alle untergeordneten Elemente eines bestimmten Namens gesucht werden können. So es beispielsweise nicht möglich, die Suche auf eine bestimmte Unterebene einzugrenzen.
Das nachfolgend gezeigte Programm durchsucht ein XML-Dokument nach Vorkommen eines Attributs innerhalb eines bestimmten Elements. Der Name des gesuchten Attributs und des Elements, in dem gesucht wird, wird als Kommandozeilen-Parameter übergeben. Die Erzeugung eines DOM-Parser-Objekts erfolgt analog zum vorhergehenden Beispiel. Wie erwähnt, ermittelt das Programm zunächst mit der Methode getElementsByTagName() eine Liste aller Vorkommen des gesuchten Elements:
Document doc;
NodeList list;
Element elNode;
String attVal;
// DOM-Baum erzeugen
doc = builder.parse(new File(args[0]));
// Liste der gesuchten Elemente holen
list = doc.getElementsByTagName(args [1]);
for (int i = 0; i < list.getLength(); i++) {
elNode = (Element)list.item(i);
// Prüfen, ob gesuchtes Attribut enthalten ist
if (elNode.hasAttribute(args[2])) {
attVal = elNode.getAttribute(args[2]);
System.out.println(args[1]+": "+args[2]+
"=\""+attVal+"\"");
}
}
Diese Knotenliste wird von der Klasse NodeList repräsentiert, die eine wichtige Hilfsklasse von DOM ist. Diese Liste wird in der for-Schleife durchgegangen, wobei bei jedem Element geprüft wird, ob es über ein Attribut mit dem gesuchten Namen verfügt. Ist das der Fall, wird der Attributwert angezeigt.
Material zum Beispiel
Copyright © 2002 dpunkt.Verlag, Heidelberg. Alle Rechte vorbehalten.